 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeaker Diarization Using Stereo Audio Channels: Preliminary Study on Utterance Clustering
Sep 10, 2020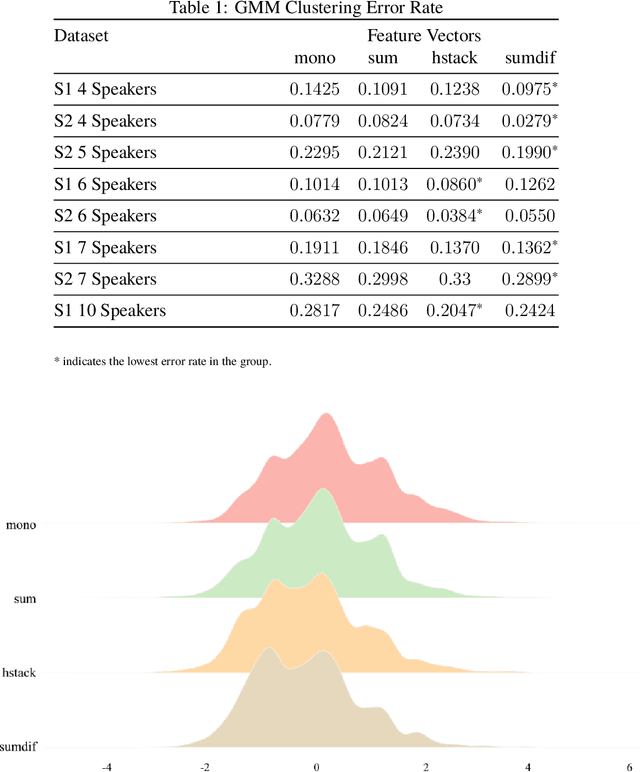
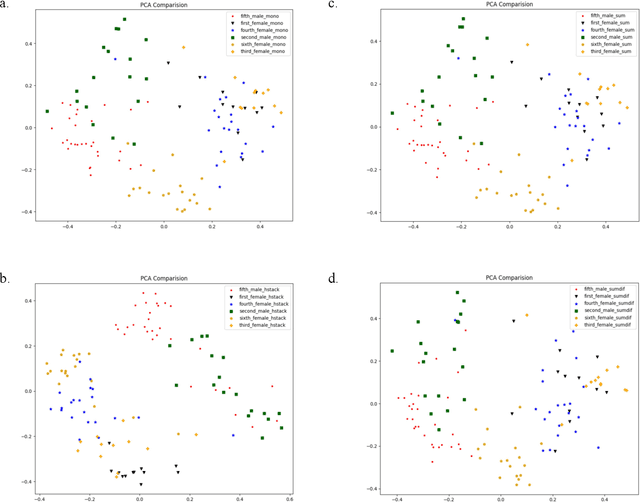
Speaker diarization is one of the actively researched topics in audio signal processing and machine learning. Utterance clustering is a critical part of a speaker diarization task. In this study, we aim to improve the performance of utterance clustering by processing multichannel (stereo) audio signals. We generated processed audio signals by combining left- and right-channel audio signals in a few different ways and then extracted embedded features (also called d-vectors) from those processed audio signals. We applied the Gaussian mixture model (GMM) for supervised utterance clustering. In the training phase, we used a parameter sharing GMM to train the model for each speaker. In the testing phase, we selected the speaker with the maximum likelihood as the detected speaker. Results of experiments with real audio recordings of multi-person discussion sessions showed that our proposed method that used multichannel audio signals achieved significantly better performance than a conventional method with mono audio signals.