 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep BI-RADS Network for Improved Cancer Detection from Mammograms
Nov 16, 2024While state-of-the-art models for breast cancer detection leverage multi-view mammograms for enhanced diagnostic accuracy, they often focus solely on visual mammography data. However, radiologists document valuable lesion descriptors that contain additional information that can enhance mammography-based breast cancer screening. A key question is whether deep learning models can benefit from these expert-derived features. To address this question, we introduce a novel multi-modal approach that combines textual BI-RADS lesion descriptors with visual mammogram content. Our method employs iterative attention layers to effectively fuse these different modalities, significantly improving classification performance over image-only models. Experiments on the CBIS-DDSM dataset demonstrate substantial improvements across all metrics, demonstrating the contribution of handcrafted features to end-to-end.
CTrGAN: Cycle Transformers GAN for Gait Transfer
Jul 01, 2022
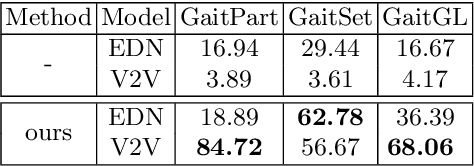
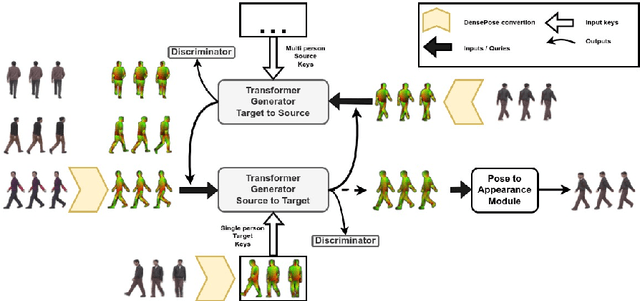
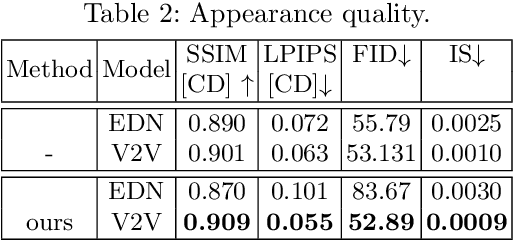
We attempt for the first time to address the problem of gait transfer. In contrast to motion transfer, the objective here is not to imitate the source's normal motions, but rather to transform the source's motion into a typical gait pattern for the target. Using gait recognition models, we demonstrate that existing techniques yield a discrepancy that can be easily detected. We introduce a novel model, Cycle Transformers GAN (CTrGAN), that can successfully generate the target's natural gait. CTrGAN's generators consist of a decoder and encoder, both Transformers, where the attention is on the temporal domain between complete images rather than the spatial domain between patches. While recent Transformer studies in computer vision mainly focused on discriminative tasks, we introduce an architecture that can be applied to synthesis tasks. Using a widely-used gait recognition dataset, we demonstrate that our approach is capable of producing over an order of magnitude more realistic personalized gaits than existing methods, even when used with sources that were not available during training.
Auto-ML Deep Learning for Rashi Scripts OCR
Nov 03, 2018



In this work we propose an OCR scheme for manuscripts printed in Rashi font that is an ancient Hebrew font and corresponding dialect used in religious Jewish literature, for more than 600 years. The proposed scheme utilizes a convolution neural network (CNN) for visual inference and Long-Short Term Memory (LSTM) to learn the Rashi scripts dialect. In particular, we derive an AutoML scheme to optimize the CNN architecture, and a book-specific CNN training to improve the OCR accuracy. The proposed scheme achieved an accuracy of more than 99.8% using a dataset of more than 3M annotated letters from the Responsa Project dataset.
Facial Landmark Point Localization using Coarse-to-Fine Deep Recurrent Neural Network
May 03, 2018
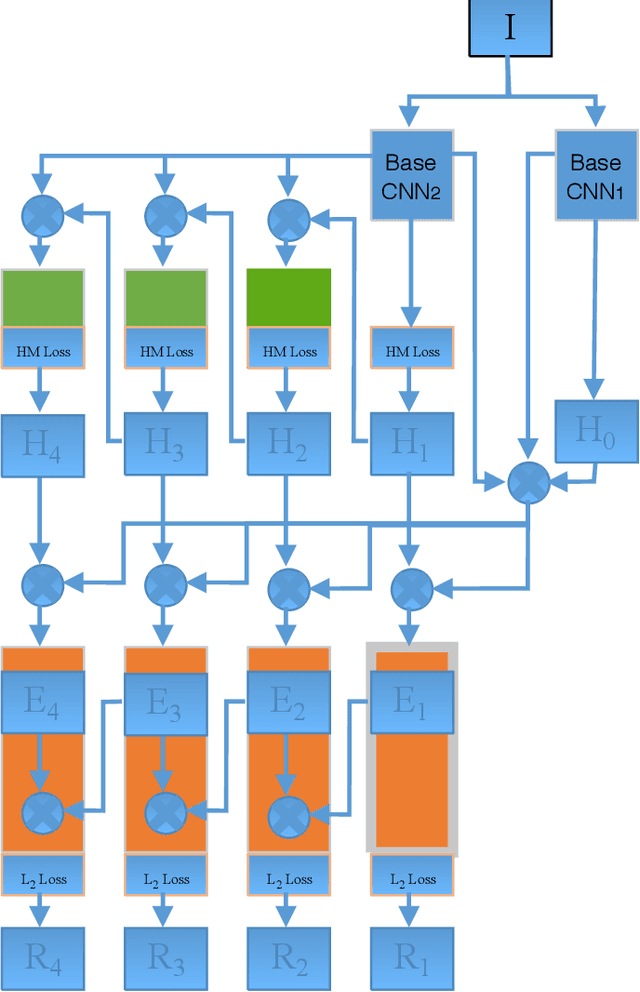
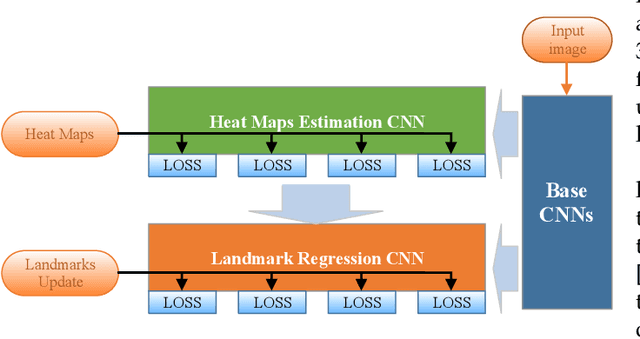
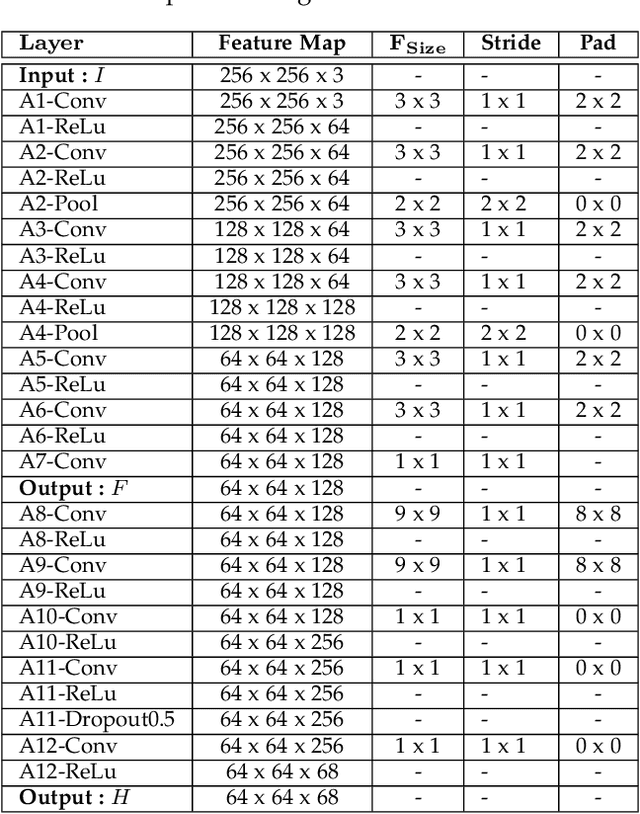
Facial landmark point localization is a typical problem in computer vision and is extensively used for increasing accuracy of face recognition, facial expression analysis, face animation etc. In recent years, substantial effort have been deployed by many researcher to design a robust facial landmark detection system. However, it still remains as one of the most challenging tasks due to the existence of extreme poses, exaggerated facial expression, unconstrained illumination, etc. In this paper, we propose a novel coarse-to-fine deep recurrent-neural-network (RNN) based framework, which uses heat-map images for facial landmark point localization. The use of heat-map images allows us using the entire face image instead of the face initialization bounding boxes or patch images around the landmark points. Performance of our proposed framework shows significant improvement in case of handling difficult face images with higher degree of occlusion, variation of pose, large yaw angles and illumination. In comparison with the best current state-of-the-art technique a reduction of 45% in failure rate and an improvement of 11.5% in area under the curve for 300-W private test set are some of the main contributions of our proposed framework.