 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSmart Fashion: A Review of AI Applications in the Fashion & Apparel Industry
Nov 02, 2021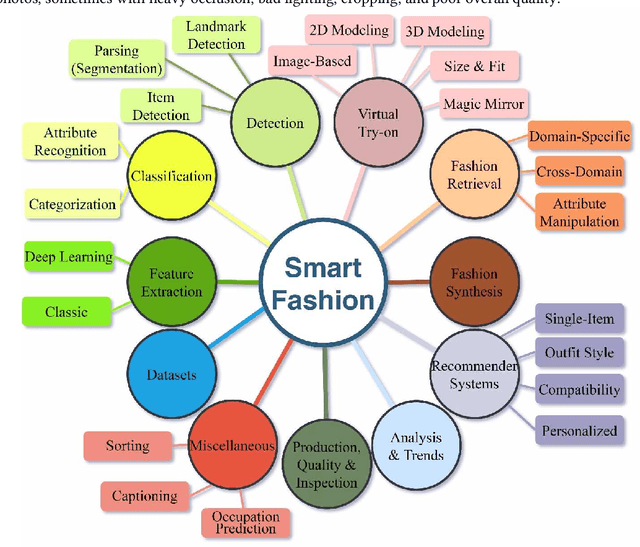
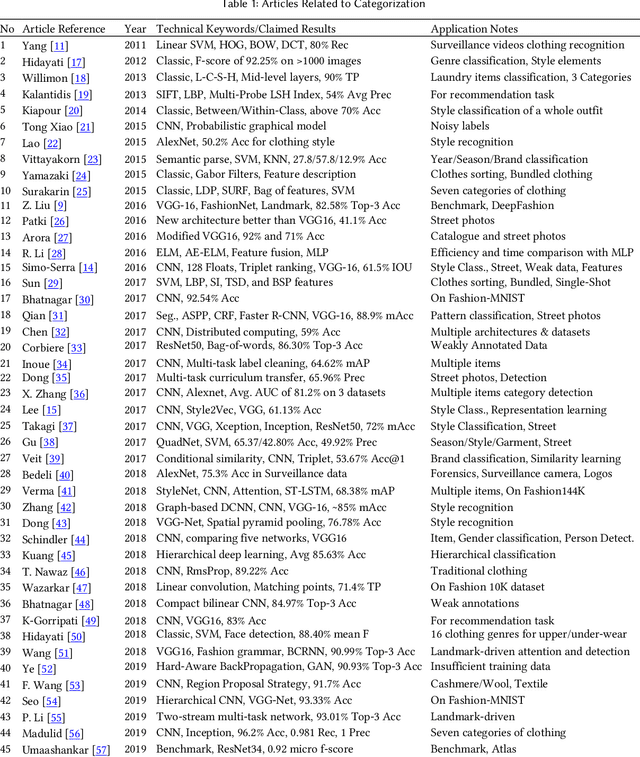

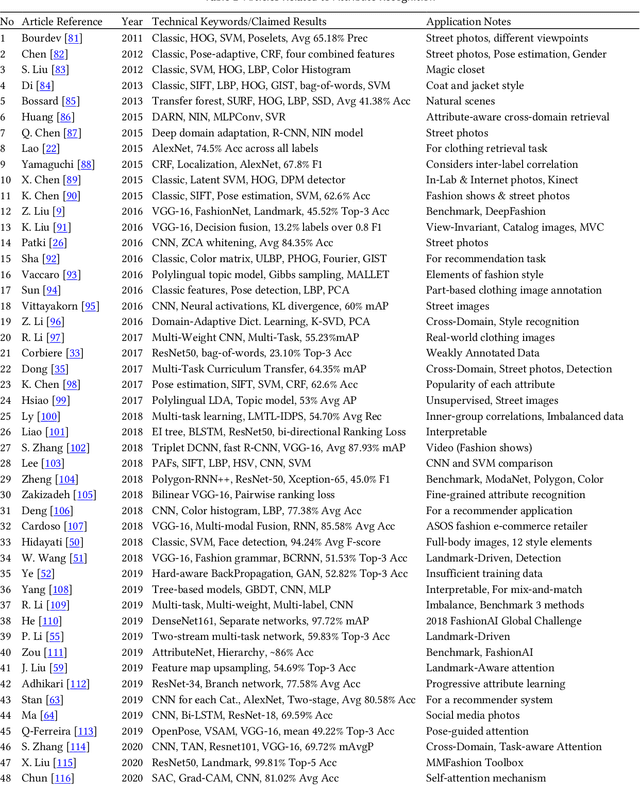
The fashion industry is on the verge of an unprecedented change. The implementation of machine learning, computer vision, and artificial intelligence (AI) in fashion applications is opening lots of new opportunities for this industry. This paper provides a comprehensive survey on this matter, categorizing more than 580 related articles into 22 well-defined fashion-related tasks. Such structured task-based multi-label classification of fashion research articles provides researchers with explicit research directions and facilitates their access to the related studies, improving the visibility of studies simultaneously. For each task, a time chart is provided to analyze the progress through the years. Furthermore, we provide a list of 86 public fashion datasets accompanied by a list of suggested applications and additional information for each.
Single-Item Fashion Recommender: Towards Cross-Domain Recommendations
Nov 01, 2021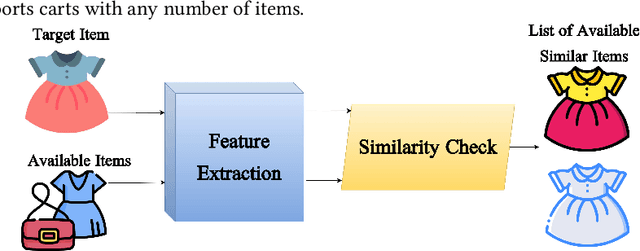
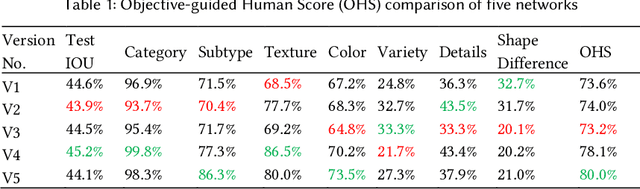


Nowadays, recommender systems and search engines play an integral role in fashion e-commerce. Still, many challenges lie ahead, and this study tries to tackle some. This article first suggests a content-based fashion recommender system that uses a parallel neural network to take a single fashion item shop image as input and make in-shop recommendations by listing similar items available in the store. Next, the same structure is enhanced to personalize the results based on user preferences. This work then introduces a background augmentation technique that makes the system more robust to out-of-domain queries, enabling it to make street-to-shop recommendations using only a training set of catalog shop images. Moreover, the last contribution of this paper is a new evaluation metric for recommendation tasks called objective-guided human score. This method is an entirely customizable framework that produces interpretable, comparable scores from subjective evaluations of human scorers.
K-Splits: Improved K-Means Clustering Algorithm to Automatically Detect the Number of Clusters
Oct 09, 2021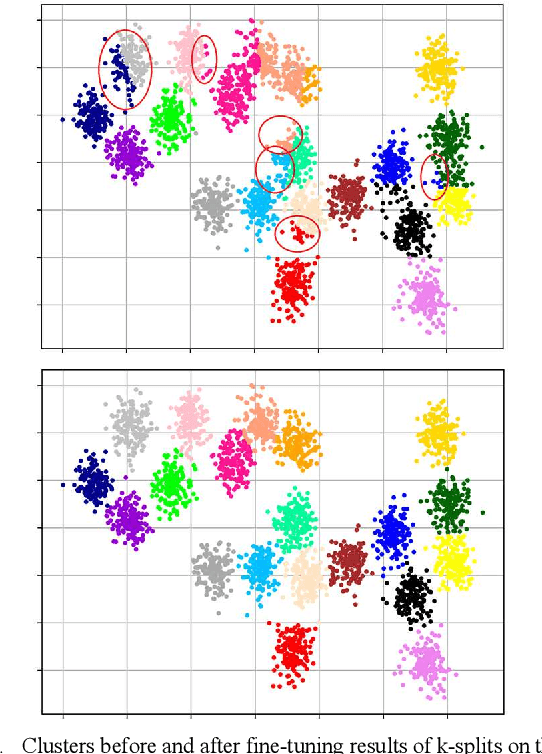
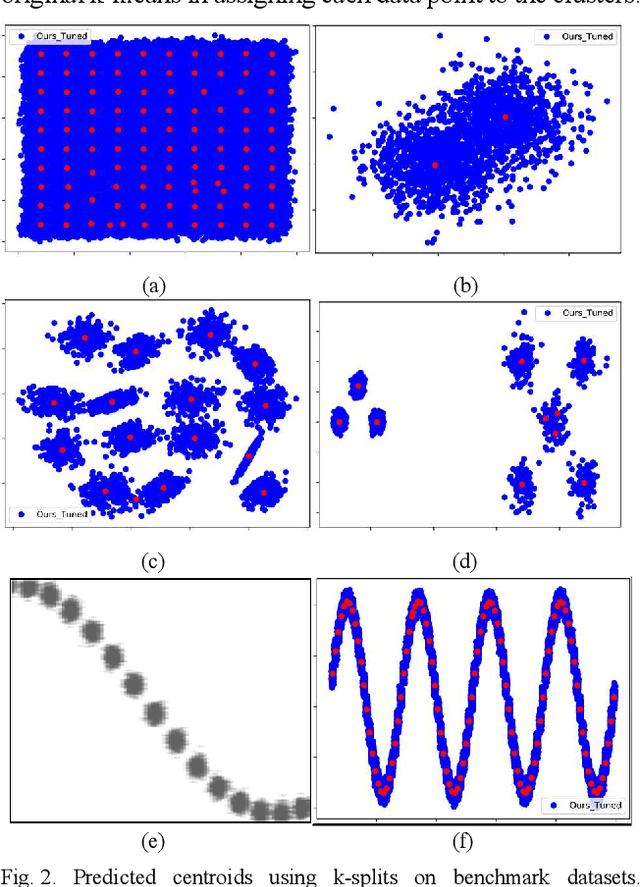
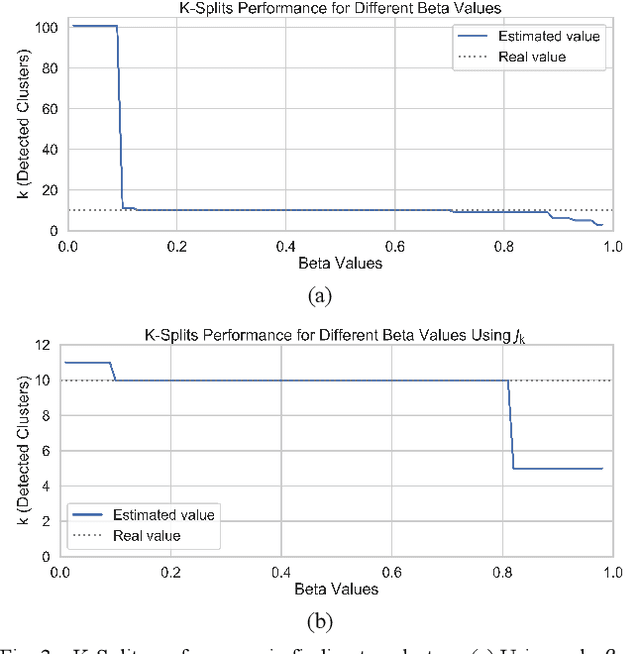
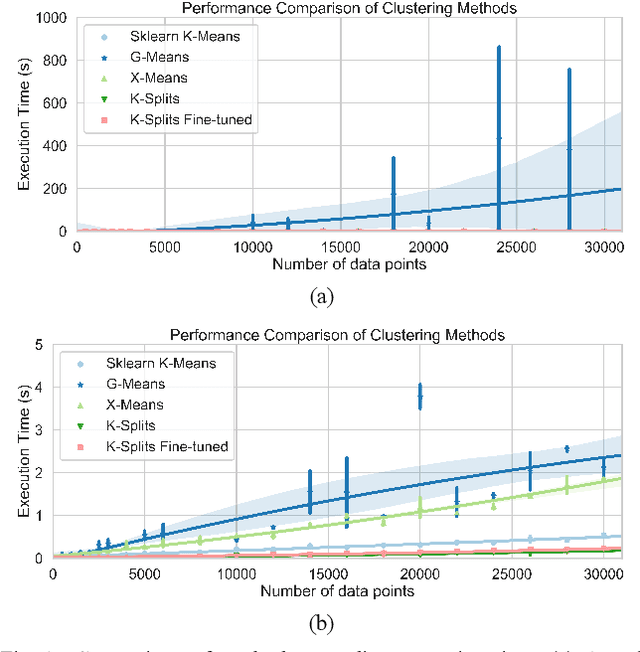
This paper introduces k-splits, an improved hierarchical algorithm based on k-means to cluster data without prior knowledge of the number of clusters. K-splits starts from a small number of clusters and uses the most significant data distribution axis to split these clusters incrementally into better fits if needed. Accuracy and speed are two main advantages of the proposed method. We experiment on six synthetic benchmark datasets plus two real-world datasets MNIST and Fashion-MNIST, to prove that our algorithm has excellent accuracy in finding the correct number of clusters under different conditions. We also show that k-splits is faster than similar methods and can even be faster than the standard k-means in lower dimensions. Finally, we suggest using k-splits to uncover the exact position of centroids and then input them as initial points to the k-means algorithm to fine-tune the results.