 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Efficient Patient Recruitment for Clinical Trials: Application of a Prompt-Based Learning Model
Apr 24, 2024

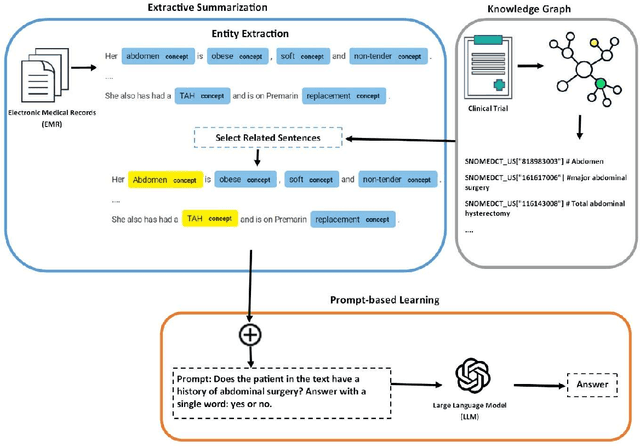

Objective: Clinical trials are essential for advancing pharmaceutical interventions, but they face a bottleneck in selecting eligible participants. Although leveraging electronic health records (EHR) for recruitment has gained popularity, the complex nature of unstructured medical texts presents challenges in efficiently identifying participants. Natural Language Processing (NLP) techniques have emerged as a solution with a recent focus on transformer models. In this study, we aimed to evaluate the performance of a prompt-based large language model for the cohort selection task from unstructured medical notes collected in the EHR. Methods: To process the medical records, we selected the most related sentences of the records to the eligibility criteria needed for the trial. The SNOMED CT concepts related to each eligibility criterion were collected. Medical records were also annotated with MedCAT based on the SNOMED CT ontology. Annotated sentences including concepts matched with the criteria-relevant terms were extracted. A prompt-based large language model (Generative Pre-trained Transformer (GPT) in this study) was then used with the extracted sentences as the training set. To assess its effectiveness, we evaluated the model's performance using the dataset from the 2018 n2c2 challenge, which aimed to classify medical records of 311 patients based on 13 eligibility criteria through NLP techniques. Results: Our proposed model showed the overall micro and macro F measures of 0.9061 and 0.8060 which were among the highest scores achieved by the experiments performed with this dataset. Conclusion: The application of a prompt-based large language model in this study to classify patients based on eligibility criteria received promising scores. Besides, we proposed a method of extractive summarization with the aid of SNOMED CT ontology that can be also applied to other medical texts.
Estimating the severity of dental and oral problems via sentiment classification over clinical reports
Jan 17, 2024Analyzing authors' sentiments in texts as a technique for identifying text polarity can be practical and useful in various fields, including medicine and dentistry. Currently, due to factors such as patients' limited knowledge about their condition, difficulties in accessing specialist doctors, or fear of illness, particularly in pandemic conditions, there might be a delay between receiving a radiology report and consulting a doctor. In some cases, this delay can pose significant risks to the patient, making timely decision-making crucial. Having an automatic system that can inform patients about the deterioration of their condition by analyzing the text of radiology reports could greatly impact timely decision-making. In this study, a dataset comprising 1,134 cone-beam computed tomography (CBCT) photo reports was collected from the Shiraz University of Medical Sciences. Each case was examined, and an expert labeled a severity level for the patient's condition on each document. After preprocessing all the text data, a deep learning model based on Convolutional Neural Network (CNN) and Long Short-Term Memory (LSTM) network architecture, known as CNN-LSTM, was developed to detect the severity level of the patient's problem based on sentiment analysis in the radiologist's report. The model's performance was evaluated on two datasets, each with two and four classes, in both imbalanced and balanced scenarios. Finally, to demonstrate the effectiveness of our model, we compared its performance with that of other classification models. The results, along with one-way ANOVA and Tukey's test, indicated that our proposed model (CNN-LSTM) performed the best according to precision, recall, and f-measure criteria. This suggests that it can be a reliable model for estimating the severity of oral and dental diseases, thereby assisting patients.