 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeObserver-based Adaptive Optimal Output Containment Control problem of Linear Heterogeneous Multi-agent Systems with Relative Output Measurements
Mar 30, 2018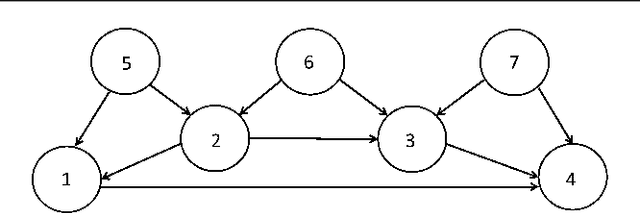
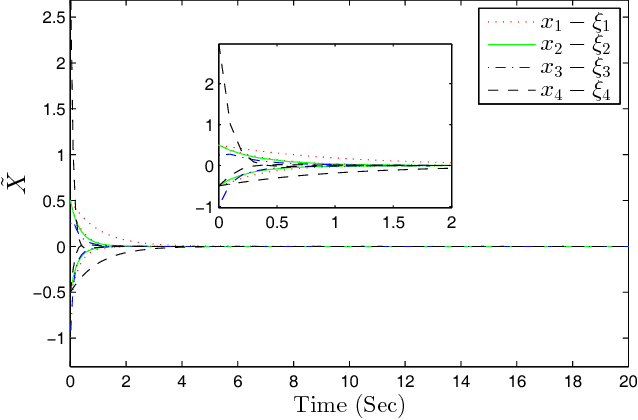
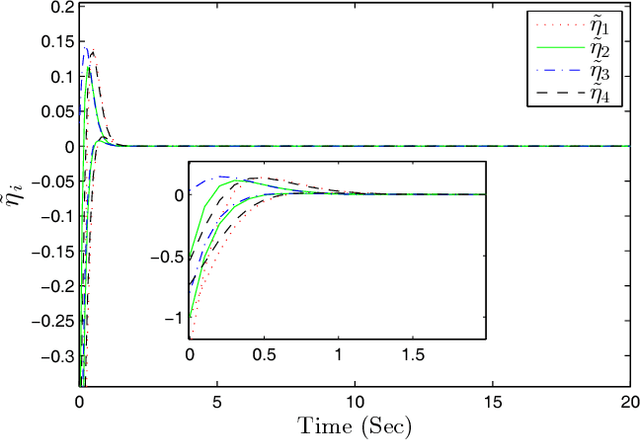
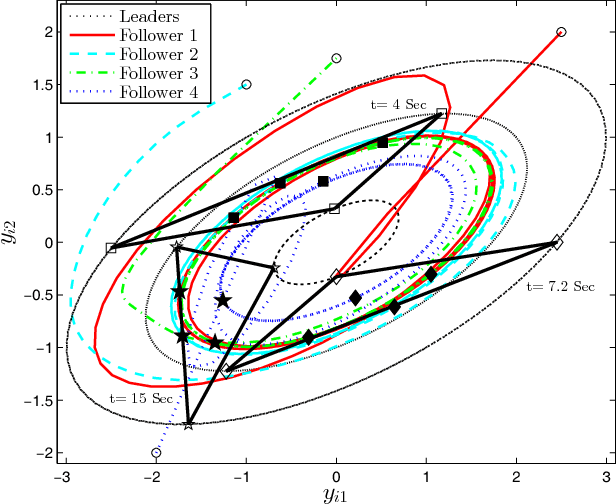
This paper develops an optimal relative output-feedback based solution to the containment control problem of linear heterogeneous multi-agent systems. A distributed optimal control protocol is presented for the followers to not only assure that their outputs fall into the convex hull of the leaders' output (i.e., the desired or safe region), but also optimizes their transient performance. The proposed optimal control solution is composed of a feedback part, depending of the followers' state, and a feed-forward part, depending on the convex hull of the leaders' state. To comply with most real-world applications, the feedback and feed-forward states are assumed to be unavailable and are estimated using two distributed observers. That is, since the followers cannot directly sense their absolute states, a distributed observer is designed that uses only relative output measurements with respect to their neighbors (measured for example by using range sensors in robotic) and the information which is broadcasted by their neighbors to estimate their states. Moreover, another adaptive distributed observer is designed that uses exchange of information between followers over a communication network to estimate the convex hull of the leaders' state. The proposed observer relaxes the restrictive requirement of knowing the complete knowledge of the leaders' dynamics by all followers. An off-policy reinforcement learning algorithm on an actor-critic structure is next developed to solve the optimal containment control problem online, using relative output measurements and without requirement of knowing the leaders' dynamics by all followers. Finally, the theoretical results are verified by numerical simulations.