 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeemojiSpace: Spatial Representation of Emojis
Sep 12, 2022
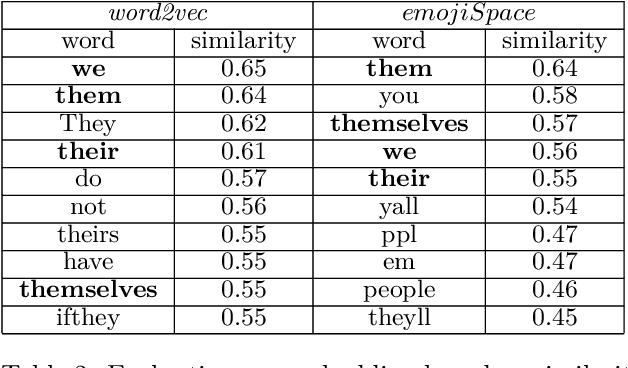

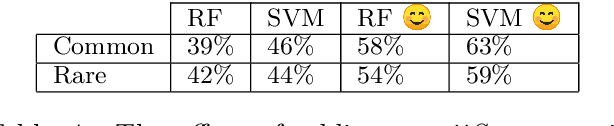
In the absence of nonverbal cues during messaging communication, users express part of their emotions using emojis. Thus, having emojis in the vocabulary of text messaging language models can significantly improve many natural language processing (NLP) applications such as online communication analysis. On the other hand, word embedding models are usually trained on a very large corpus of text such as Wikipedia or Google News datasets that include very few samples with emojis. In this study, we create emojiSpace, which is a combined word-emoji embedding using the word2vec model from the Genism library in Python. We trained emojiSpace on a corpus of more than 4 billion tweets and evaluated it by implementing sentiment analysis on a Twitter dataset containing more than 67 million tweets as an extrinsic task. For this task, we compared the performance of two different classifiers of random forest (RF) and linear support vector machine (SVM). For evaluation, we compared emojiSpace performance with two other pre-trained embeddings and demonstrated that emojiSpace outperforms both.