 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-Modal Bottleneck Fusion For Noise Robust Audio-Visual Speech Recognition
Feb 09, 2026Audio-Visual Speech Recognition (AVSR) leverages both acoustic and visual cues to improve speech recognition under noisy conditions. A central question is how to design a fusion mechanism that allows the model to effectively exploit visual information when the audio signal is degraded, while maintaining strong performance on clean speech. We propose CoBRA (Cross-modal Bottleneck for Robust AVSR), a bottleneck-based fusion framework that introduces a compact set of learnable tokens to mediate cross-modal exchange. By regulating information flow through these tokens, the audio stream can reliably access essential visual cues even under adverse or out-of-domain noise. Despite limited training data, our model surpasses comparable baselines and remains competitive with large-scale systems through noise-adaptive fusion, demonstrating both efficiency and robustness. Ablation studies highlight that the depth of fusion is the most critical factor, underscoring its importance in designing robust AVSR systems.
Rethinking Speech Representation Aggregation in Speech Enhancement: A Phonetic Mutual Information Perspective
Jan 30, 2026Recent speech enhancement (SE) models increasingly leverage self-supervised learning (SSL) representations for their rich semantic information. Typically, intermediate features are aggregated into a single representation via a lightweight adaptation module. However, most SSL models are not trained for noise robustness, which can lead to corrupted semantic representations. Moreover, the adaptation module is trained jointly with the SE model, potentially prioritizing acoustic details over semantic information, contradicting the original purpose. To address this issue, we first analyze the behavior of SSL models on noisy speech from an information-theoretic perspective. Specifically, we measure the mutual information (MI) between the corrupted SSL representations and the corresponding phoneme labels, focusing on preservation of linguistic contents. Building upon this analysis, we introduce the linguistic aggregation layer, which is pre-trained to maximize MI with phoneme labels (with optional dynamic aggregation) and then frozen during SE training. Experiments show that this decoupled approach improves Word Error Rate (WER) over jointly optimized baselines, demonstrating the benefit of explicitly aligning the adaptation module with linguistic contents.
Differentiable Acoustic Radiance Transfer
Sep 19, 2025Geometric acoustics is an efficient approach to room acoustics modeling, governed by the canonical time-dependent rendering equation. Acoustic radiance transfer (ART) solves the equation through discretization, modeling the time- and direction-dependent energy exchange between surface patches given with flexible material properties. We introduce DART, a differentiable and efficient implementation of ART that enables gradient-based optimization of material properties. We evaluate DART on a simpler variant of the acoustic field learning task, which aims to predict the energy responses of novel source-receiver settings. Experimental results show that DART exhibits favorable properties, e.g., better generalization under a sparse measurement scenario, compared to existing signal processing and neural network baselines, while remaining a simple, fully interpretable system.
PhaseAug: A Differentiable Augmentation for Speech Synthesis to Simulate One-to-Many Mapping
Nov 08, 2022



Previous generative adversarial network (GAN)-based neural vocoders are trained to reconstruct the exact ground truth waveform from the paired mel-spectrogram and do not consider the one-to-many relationship of speech synthesis. This conventional training causes overfitting for both the discriminators and the generator, leading to the periodicity artifacts in the generated audio signal. In this work, we present PhaseAug, the first differentiable augmentation for speech synthesis that rotates the phase of each frequency bin to simulate one-to-many mapping. With our proposed method, we outperform baselines without any architecture modification. Code and audio samples will be available at https://github.com/mindslab-ai/phaseaug.
NU-Wave 2: A General Neural Audio Upsampling Model for Various Sampling Rates
Jun 17, 2022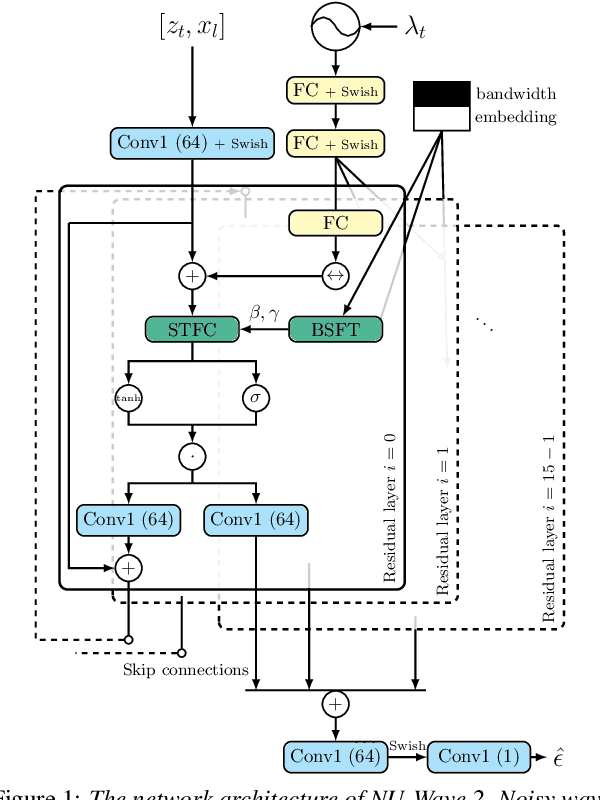
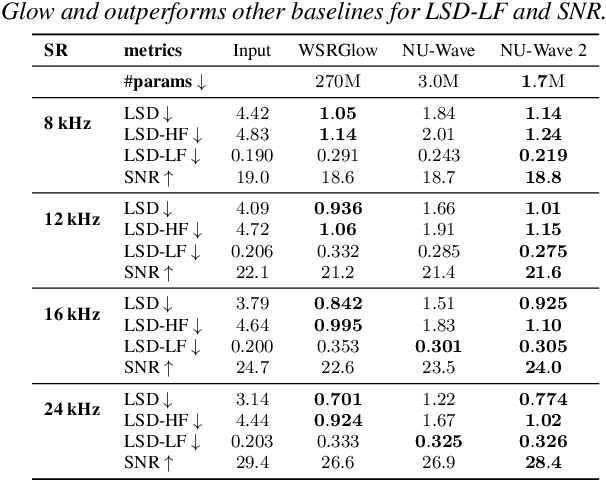
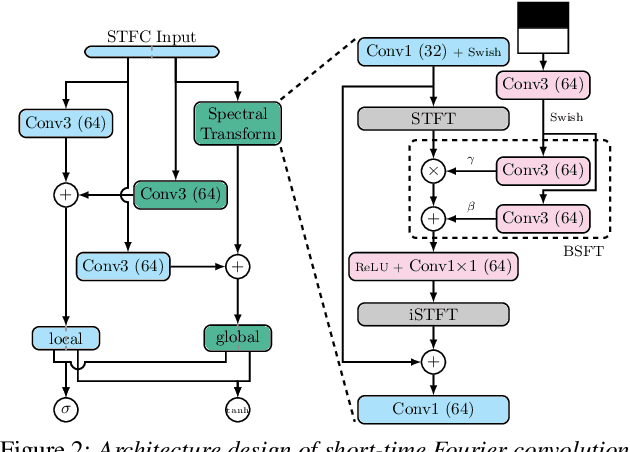
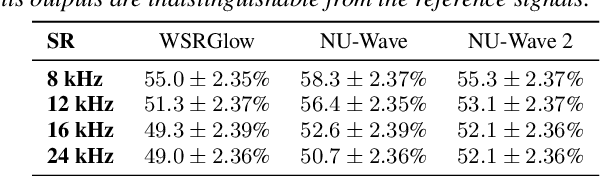
Conventionally, audio super-resolution models fixed the initial and the target sampling rates, which necessitate the model to be trained for each pair of sampling rates. We introduce NU-Wave 2, a diffusion model for neural audio upsampling that enables the generation of 48 kHz audio signals from inputs of various sampling rates with a single model. Based on the architecture of NU-Wave, NU-Wave 2 uses short-time Fourier convolution (STFC) to generate harmonics to resolve the main failure modes of NU-Wave, and incorporates bandwidth spectral feature transform (BSFT) to condition the bandwidths of inputs in the frequency domain. We experimentally demonstrate that NU-Wave 2 produces high-resolution audio regardless of the sampling rate of input while requiring fewer parameters than other models. The official code and the audio samples are available at https://mindslab-ai.github.io/nuwave2.
NU-Wave: A Diffusion Probabilistic Model for Neural Audio Upsampling
Apr 06, 2021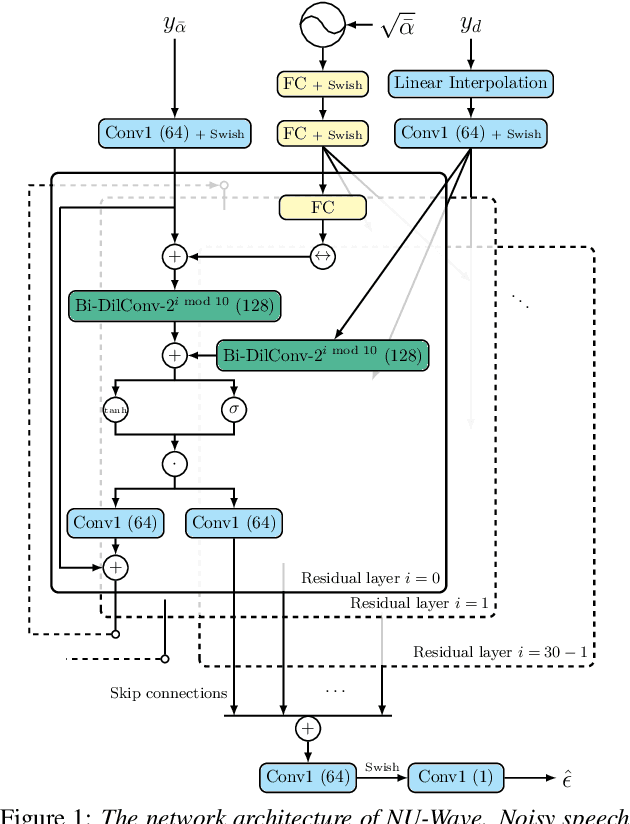

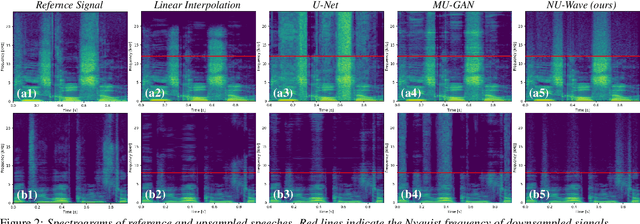
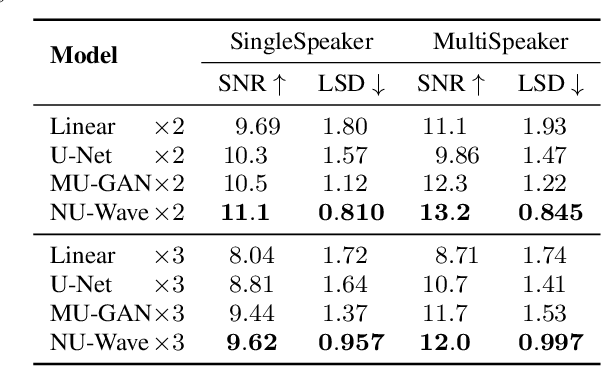
In this work, we introduce NU-Wave, the first neural audio upsampling model to produce waveforms of sampling rate 48kHz from coarse 16kHz or 24kHz inputs, while prior works could generate only up to 16kHz. NU-Wave is the first diffusion probabilistic model for audio super-resolution which is engineered based on neural vocoders. NU-Wave generates high-quality audio that achieves high performance in terms of signal-to-noise ratio (SNR), log-spectral distance (LSD), and accuracy of the ABX test. In all cases, NU-Wave outperforms the baseline models despite the substantially smaller model capacity (3.0M parameters) than baselines (5.4-21%). The audio samples of our model are available at https://mindslab-ai.github.io/nuwave, and the code will be made available soon.