 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCollocation2Text: Controllable Text Generation from Guide Phrases in Russian
Jun 18, 2022
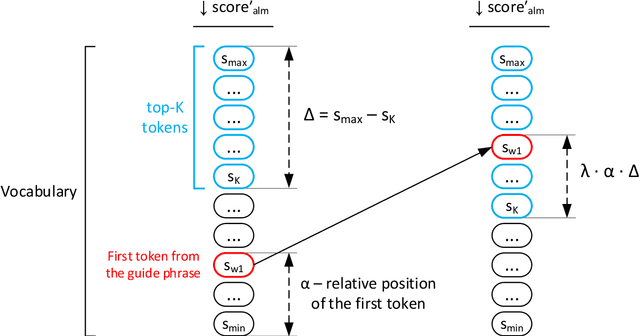
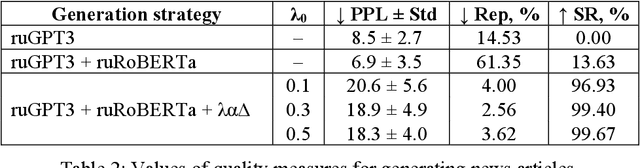
Large pre-trained language models are capable of generating varied and fluent texts. Starting from the prompt, these models generate a narrative that can develop unpredictably. The existing methods of controllable text generation, which guide the narrative in the text in the user-specified direction, require creating a training corpus and an additional time-consuming training procedure. The paper proposes and investigates Collocation2Text, a plug-and-play method for automatic controllable text generation in Russian, which does not require fine-tuning. The method is based on two interacting models: the autoregressive language ruGPT-3 model and the autoencoding language ruRoBERTa model. The idea of the method is to shift the output distribution of the autoregressive model according to the output distribution of the autoencoding model in order to ensure a coherent transition of the narrative in the text towards the guide phrase, which can contain single words or collocations. The autoencoding model, which is able to take into account the left and right contexts of the token, "tells" the autoregressive model which tokens are the most and least logical at the current generation step, increasing or decreasing the probabilities of the corresponding tokens. The experiments on generating news articles using the proposed method showed its effectiveness for automatically generated fluent texts which contain coherent transitions between user-specified phrases.
Does BERT look at sentiment lexicon?
Nov 19, 2021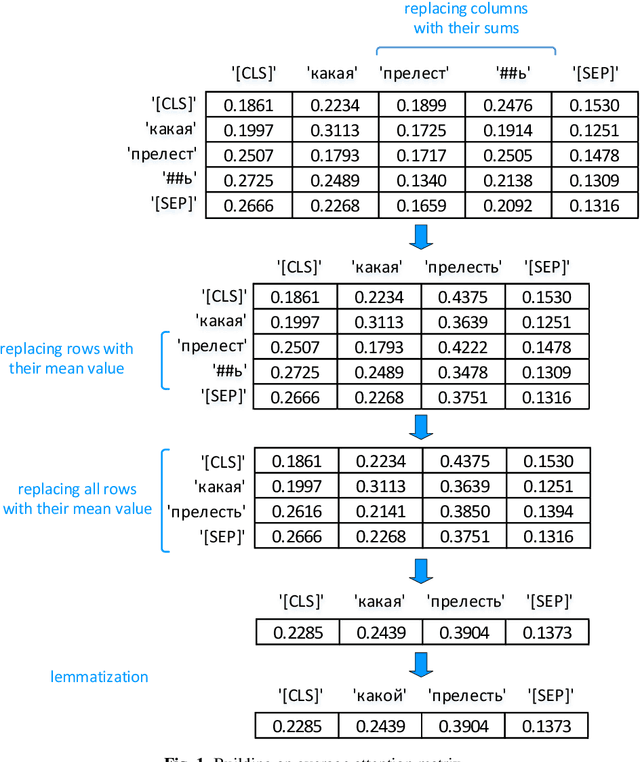

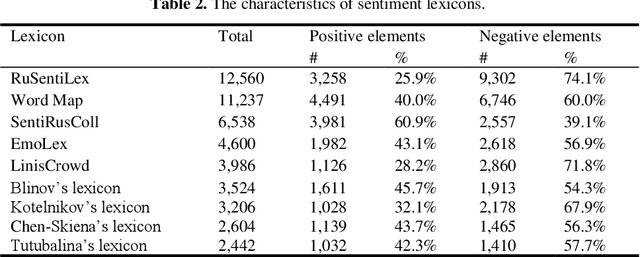
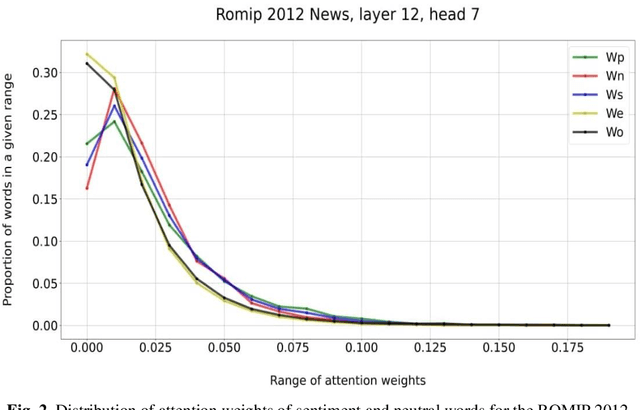
The main approaches to sentiment analysis are rule-based methods and ma-chine learning, in particular, deep neural network models with the Trans-former architecture, including BERT. The performance of neural network models in the tasks of sentiment analysis is superior to the performance of rule-based methods. The reasons for this situation remain unclear due to the poor interpretability of deep neural network models. One of the main keys to understanding the fundamental differences between the two approaches is the analysis of how sentiment lexicon is taken into account in neural network models. To this end, we study the attention weights matrices of the Russian-language RuBERT model. We fine-tune RuBERT on sentiment text corpora and compare the distributions of attention weights for sentiment and neutral lexicons. It turns out that, on average, 3/4 of the heads of various model var-iants statistically pay more attention to the sentiment lexicon compared to the neutral one.