 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical Deep Learning Architecture For 10K Objects Classification
Sep 07, 2015
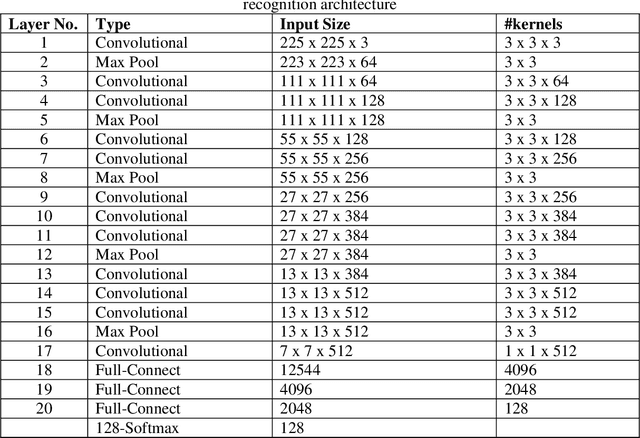
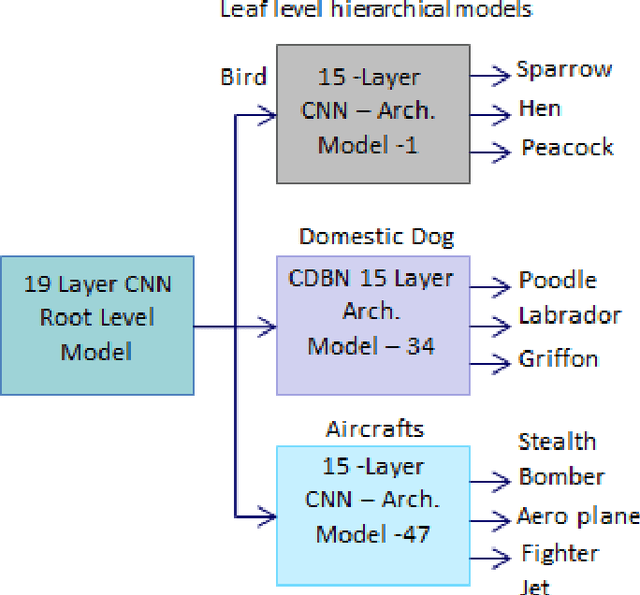
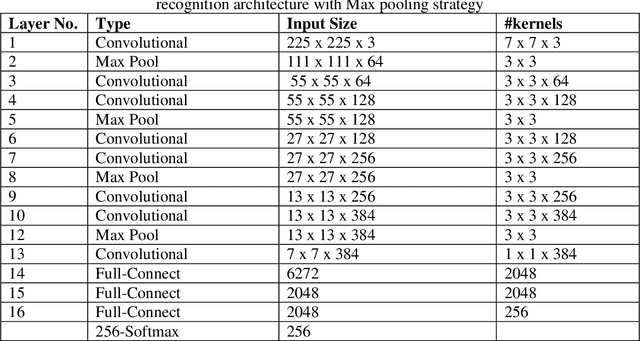
Evolution of visual object recognition architectures based on Convolutional Neural Networks & Convolutional Deep Belief Networks paradigms has revolutionized artificial Vision Science. These architectures extract & learn the real world hierarchical visual features utilizing supervised & unsupervised learning approaches respectively. Both the approaches yet cannot scale up realistically to provide recognition for a very large number of objects as high as 10K. We propose a two level hierarchical deep learning architecture inspired by divide & conquer principle that decomposes the large scale recognition architecture into root & leaf level model architectures. Each of the root & leaf level models is trained exclusively to provide superior results than possible by any 1-level deep learning architecture prevalent today. The proposed architecture classifies objects in two steps. In the first step the root level model classifies the object in a high level category. In the second step, the leaf level recognition model for the recognized high level category is selected among all the leaf models. This leaf level model is presented with the same input object image which classifies it in a specific category. Also we propose a blend of leaf level models trained with either supervised or unsupervised learning approaches. Unsupervised learning is suitable whenever labelled data is scarce for the specific leaf level models. Currently the training of leaf level models is in progress; where we have trained 25 out of the total 47 leaf level models as of now. We have trained the leaf models with the best case top-5 error rate of 3.2% on the validation data set for the particular leaf models. Also we demonstrate that the validation error of the leaf level models saturates towards the above mentioned accuracy as the number of epochs are increased to more than sixty.
* As appeared in proceedings for CS & IT 2015 - Second International Conference on Computer Science & Engineering (CSEN 2015)