 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCrime Analysis using Open Source Information
Feb 15, 2019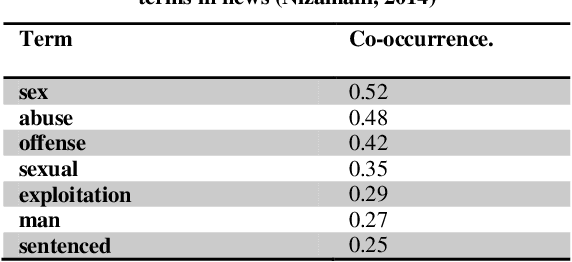
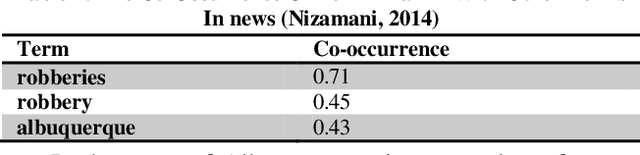
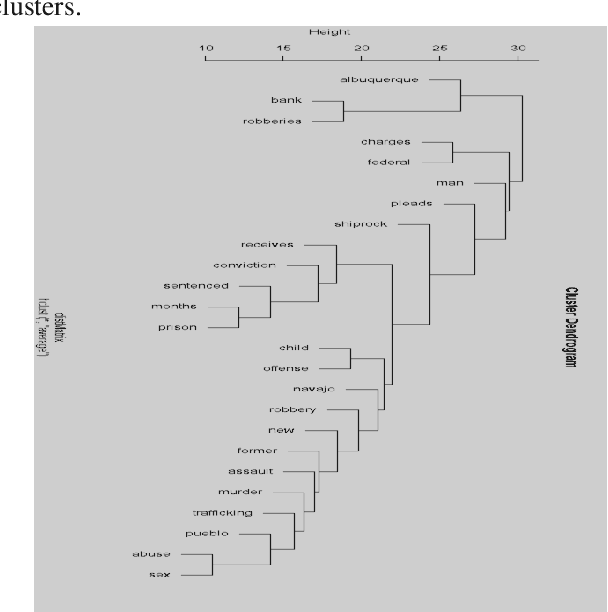
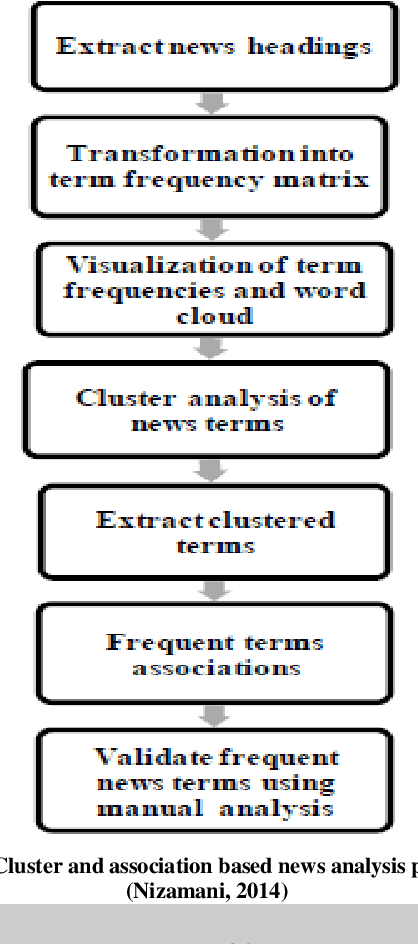
In this paper, we present a method of crime analysis from open source information. We employed un-supervised methods of data mining to explore the facts regarding the crimes of an area of interest. The analysis is based on well known clustering and association techniques. The results show that the proposed method of crime analysis is efficient and gives a broad picture of the crimes of an area to analyst without much effort. The analysis is evaluated using manual approach, which reveals that the results produced by the proposed approach are comparable to the manual analysis, while a great amount of time is saved.
Modeling Suspicious Email Detection using Enhanced Feature Selection
Dec 06, 2013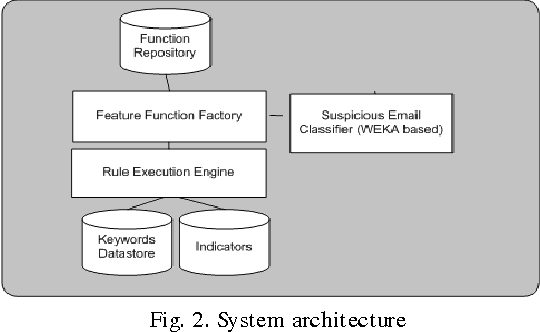


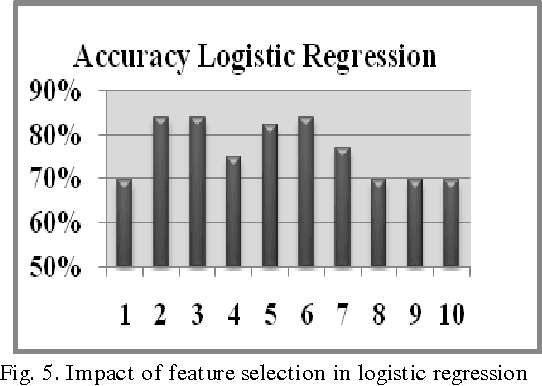
The paper presents a suspicious email detection model which incorporates enhanced feature selection. In the paper we proposed the use of feature selection strategies along with classification technique for terrorists email detection. The presented model focuses on the evaluation of machine learning algorithms such as decision tree (ID3), logistic regression, Na\"ive Bayes (NB), and Support Vector Machine (SVM) for detecting emails containing suspicious content. In the literature, various algorithms achieved good accuracy for the desired task. However, the results achieved by those algorithms can be further improved by using appropriate feature selection mechanisms. We have identified the use of a specific feature selection scheme that improves the performance of the existing algorithms.
CEAI: CCM based Email Authorship Identification Model
Dec 06, 2013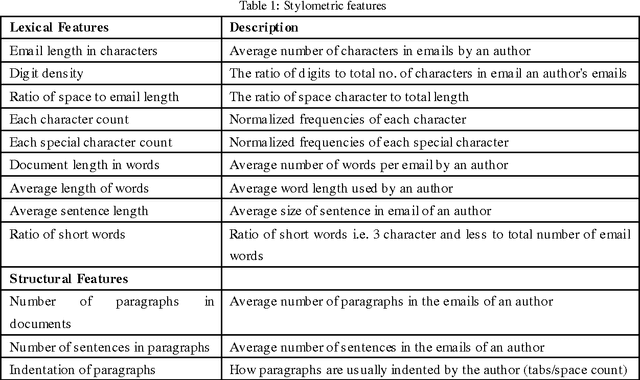
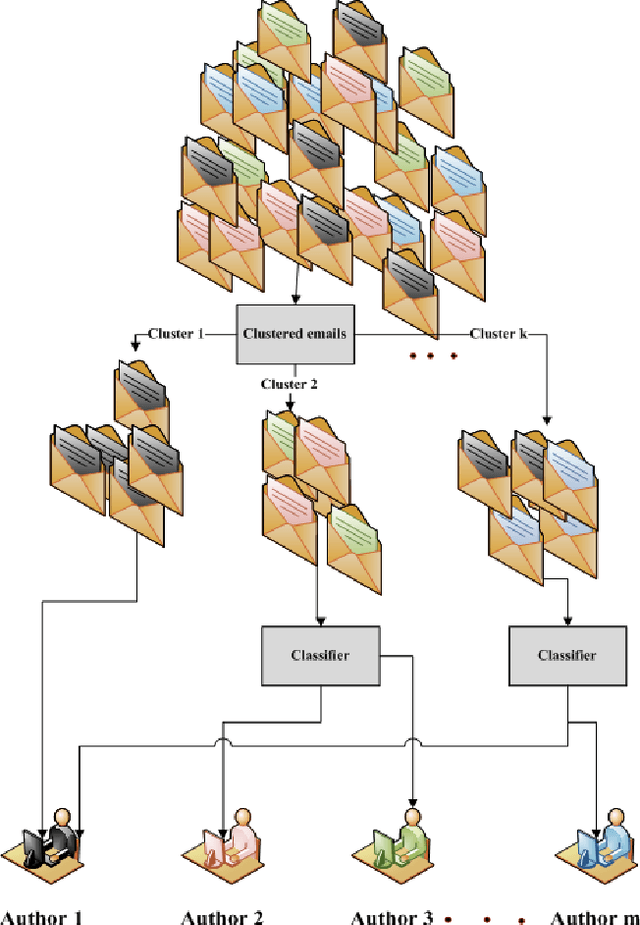
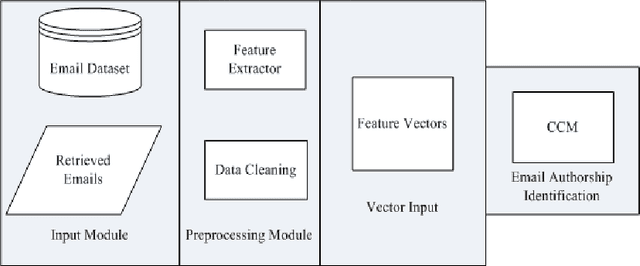
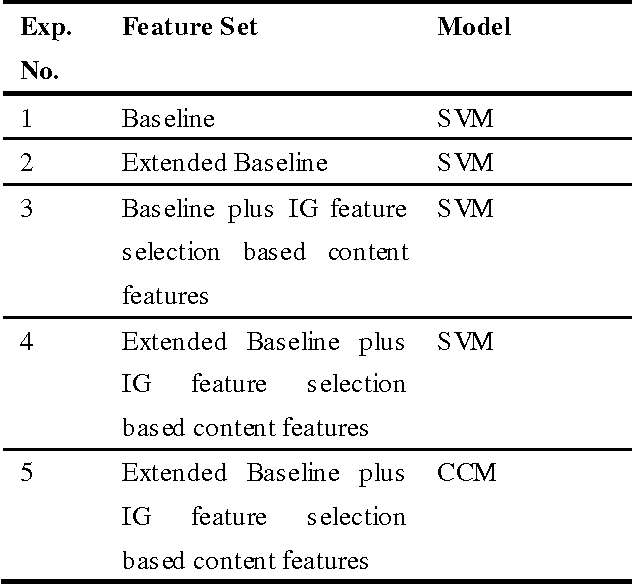
In this paper we present a model for email authorship identification (EAI) by employing a Cluster-based Classification (CCM) technique. Traditionally, stylometric features have been successfully employed in various authorship analysis tasks; we extend the traditional feature-set to include some more interesting and effective features for email authorship identification (e.g. the last punctuation mark used in an email, the tendency of an author to use capitalization at the start of an email, or the punctuation after a greeting or farewell). We also included Info Gain feature selection based content features. It is observed that the use of such features in the authorship identification process has a positive impact on the accuracy of the authorship identification task. We performed experiments to justify our arguments and compared the results with other base line models. Experimental results reveal that the proposed CCM-based email authorship identification model, along with the proposed feature set, outperforms the state-of-the-art support vector machine (SVM)-based models, as well as the models proposed by Iqbal et al. [1, 2]. The proposed model attains an accuracy rate of 94% for 10 authors, 89% for 25 authors, and 81% for 50 authors, respectively on Enron dataset, while 89.5% accuracy has been achieved on authors' constructed real email dataset. The results on Enron dataset have been achieved on quite a large number of authors as compared to the models proposed by Iqbal et al. [1, 2].