 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCNN based Extraction of Panels/Characters from Bengali Comic Book Page Images
Oct 21, 2019



Peoples nowadays prefer to use digital gadgets like cameras or mobile phones for capturing documents. Automatic extraction of panels/characters from the images of a comic document is challenging due to the wide variety of drawing styles adopted by writers, beneficial for readers to read them on mobile devices at any time and useful for automatic digitization. Most of the methods for localization of panel/character rely on the connected component analysis or page background mask and are applicable only for a limited comic dataset. This work proposes a panel/character localization architecture based on the features of YOLO and CNN for extraction of both panels and characters from comic book images. The method achieved remarkable results on Bengali Comic Book Image dataset (BCBId) consisting of total $4130$ images, developed by us as well as on a variety of publicly available comic datasets in other languages, i.e. eBDtheque, Manga 109 and DCM dataset.
A Method to Generate Synthetically Warped Document Image
Oct 15, 2019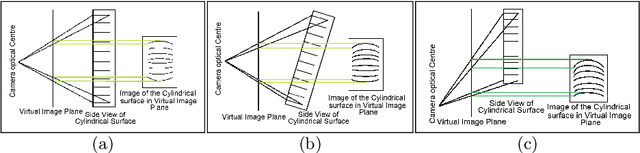

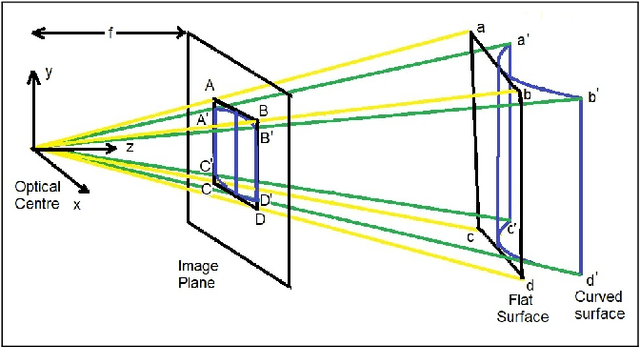

The digital camera captured document images may often be warped and distorted due to different camera angles or document surfaces. A robust technique is needed to solve this kind of distortion. The research on dewarping of the document suffers due to the limited availability of benchmark public dataset. In recent times, deep learning based approaches are used to solve the problems accurately. To train most of the deep neural networks a large number of document images is required and generating such a large volume of document images manually is difficult. In this paper, we propose a technique to generate a synthetic warped image from a flat-bedded scanned document image. It is done by calculating warping factors for each pixel position using two warping position parameters (WPP) and eight warping control parameters (WCP). These parameters can be specified as needed depending upon the desired warping. The results are compared with similar real captured images both qualitative and quantitative way.