 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMODP: Multi Objective Directional Prompting
Apr 25, 2025


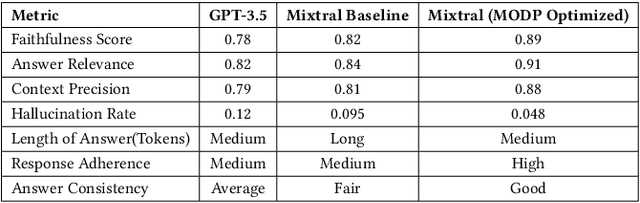
Recent advances in large language models (LLMs) have led to their popularity across multiple use-cases. However, prompt engineering, the process for optimally utilizing such models, remains approximation-driven and subjective. Most of the current research on prompt engineering focuses on task-specific optimization, while neglecting the behavior of the LLM under consideration during prompt development. This paper introduces MODP -- Multi Objective Directional Prompting, a framework based on two key concepts: 1) multi-objectivity: the importance of considering an LLM's intrinsic behavior as an additional objective in prompt development, and 2) directional prompting: a metrics-driven method for prompt engineering to ensure development of robust and high-precision prompts. We demonstrate the effectiveness of our proposed ideas on a summarization task, using a synthetically created dataset, achieving a 26% performance gain over initial prompts. Finally, we apply MODP to develop prompts for Dell's Next Best Action support tool, which is now in production and is used by more than 10,000 internal support agents and serving millions of customers worldwide.
Fashion Recommendation: Outfit Compatibility using GNN
Apr 28, 2024Numerous industries have benefited from the use of machine learning and fashion in industry is no exception. By gaining a better understanding of what makes a good outfit, companies can provide useful product recommendations to their users. In this project, we follow two existing approaches that employ graphs to represent outfits and use modified versions of the Graph neural network (GNN) frameworks. Both Node-wise Graph Neural Network (NGNN) and Hypergraph Neural Network aim to score a set of items according to the outfit compatibility of items. The data used is the Polyvore Dataset which consists of curated outfits with product images and text descriptions for each product in an outfit. We recreate the analysis on a subset of this data and compare the two existing models on their performance on two tasks Fill in the blank (FITB): finding an item that completes an outfit, and Compatibility prediction: estimating compatibility of different items grouped as an outfit. We can replicate the results directionally and find that HGNN does have a slightly better performance on both tasks. On top of replicating the results of the two papers we also tried to use embeddings generated from a vision transformer and witness enhanced prediction accuracy across the board
Efficacy of Machine-Generated Instructions
Dec 22, 2023Large "instruction-tuned" language models (i.e., finetuned to respond to instructions) have demonstrated a remarkable ability to generalize zero-shot to new tasks. Nevertheless, they depend heavily on human-written instruction data that is often limited in quantity, diversity, and creativity, therefore hindering the generality of the tuned model. We conducted a quantitative study to figure out the efficacy of machine-generated annotations, where we compare the results of a fine-tuned BERT model with human v/s machine-generated annotations. Applying our methods to the vanilla GPT-3 model, we saw that machine generated annotations were 78.54% correct and the fine-tuned model achieved a 96.01% model performance compared to the performance with human-labelled annotations. This result shows that machine-generated annotations are a resource and cost effective way to fine-tune down-stream models.