 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCheckovid: A COVID-19 misinformation detection system on Twitter using network and content mining perspectives
Jul 20, 2021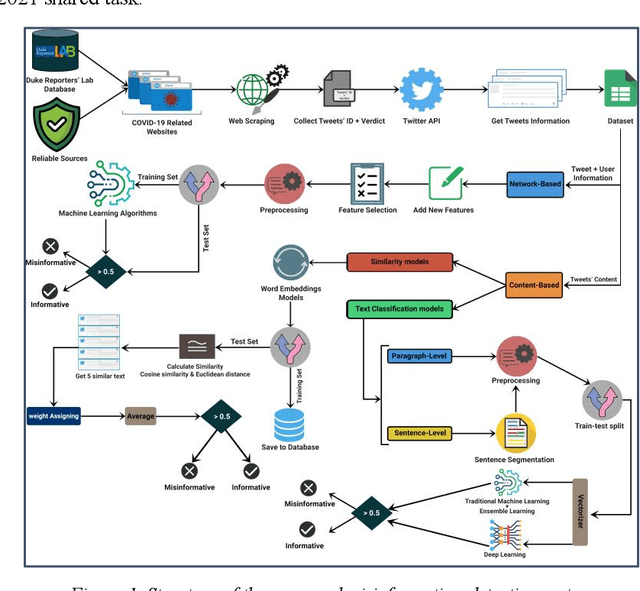

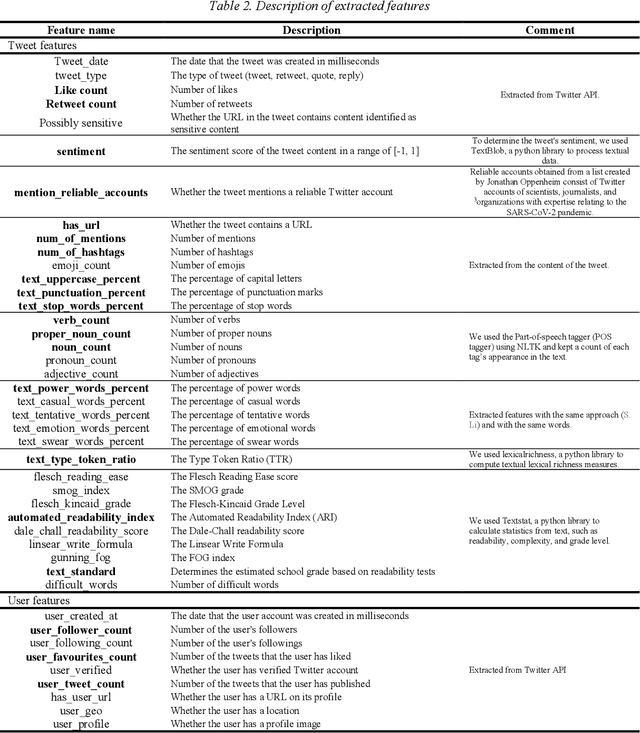
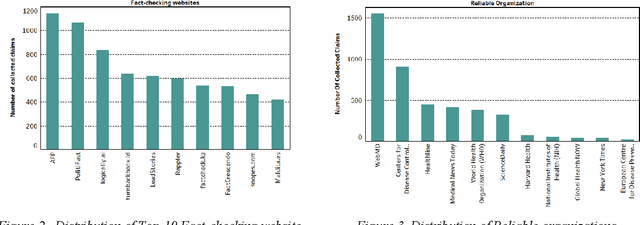
During the COVID-19 pandemic, social media platforms were ideal for communicating due to social isolation and quarantine. Also, it was the primary source of misinformation dissemination on a large scale, referred to as the infodemic. Therefore, automatic debunking misinformation is a crucial problem. To tackle this problem, we present two COVID-19 related misinformation datasets on Twitter and propose a misinformation detection system comprising network-based and content-based processes based on machine learning algorithms and NLP techniques. In the network-based process, we focus on social properties, network characteristics, and users. On the other hand, we classify misinformation using the content of the tweets directly in the content-based process, which contains text classification models (paragraph-level and sentence-level) and similarity models. The evaluation results on the network-based process show the best results for the artificial neural network model with an F1 score of 88.68%. In the content-based process, our novel similarity models, which obtained an F1 score of 90.26%, show an improvement in the misinformation classification results compared to the network-based models. In addition, in the text classification models, the best result was achieved using the stacking ensemble-learning model by obtaining an F1 score of 95.18%. Furthermore, we test our content-based models on the Constraint@AAAI2021 dataset, and by getting an F1 score of 94.38%, we improve the baseline results. Finally, we develop a fact-checking website called Checkovid that uses each process to detect misinformative and informative claims in the domain of COVID-19 from different perspectives.