 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDNNShield: Dynamic Randomized Model Sparsification, A Defense Against Adversarial Machine Learning
Jul 31, 2022
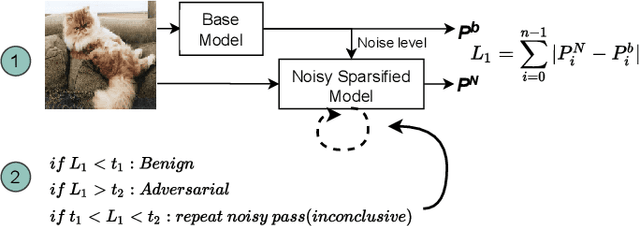
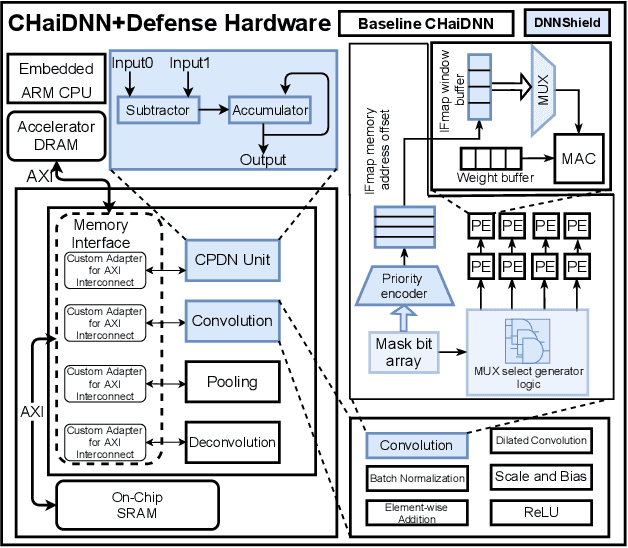
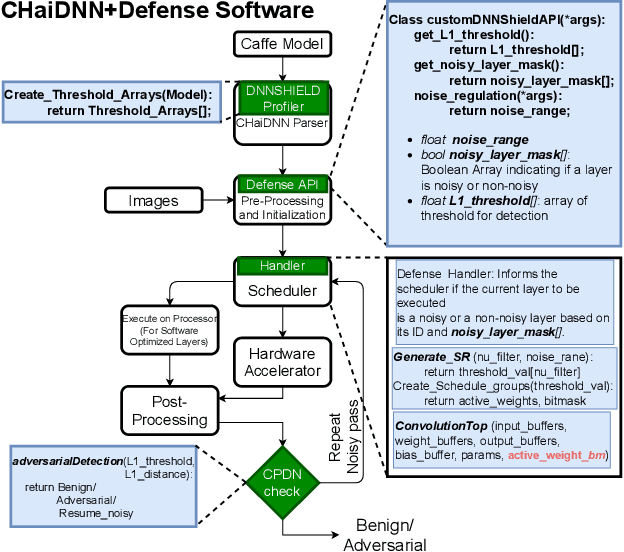
DNNs are known to be vulnerable to so-called adversarial attacks that manipulate inputs to cause incorrect results that can be beneficial to an attacker or damaging to the victim. Recent works have proposed approximate computation as a defense mechanism against machine learning attacks. We show that these approaches, while successful for a range of inputs, are insufficient to address stronger, high-confidence adversarial attacks. To address this, we propose DNNSHIELD, a hardware-accelerated defense that adapts the strength of the response to the confidence of the adversarial input. Our approach relies on dynamic and random sparsification of the DNN model to achieve inference approximation efficiently and with fine-grain control over the approximation error. DNNSHIELD uses the output distribution characteristics of sparsified inference compared to a dense reference to detect adversarial inputs. We show an adversarial detection rate of 86% when applied to VGG16 and 88% when applied to ResNet50, which exceeds the detection rate of the state of the art approaches, with a much lower overhead. We demonstrate a software/hardware-accelerated FPGA prototype, which reduces the performance impact of DNNSHIELD relative to software-only CPU and GPU implementations.
Using Undervolting as an On-Device Defense Against Adversarial Machine Learning Attacks
Aug 06, 2021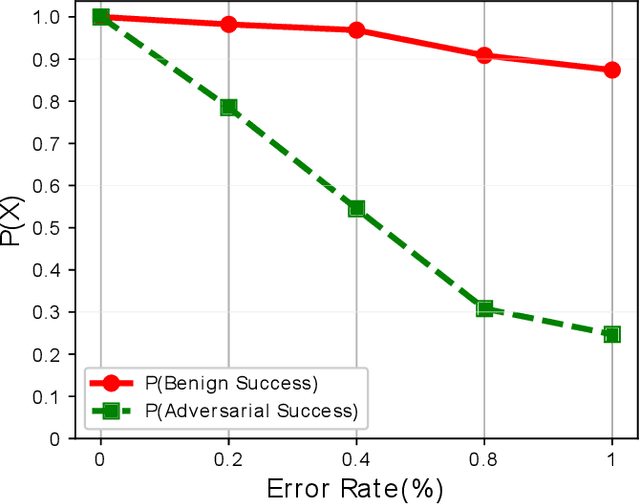
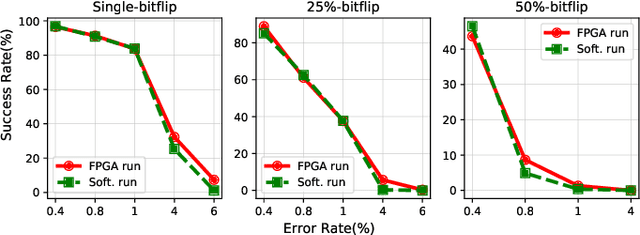

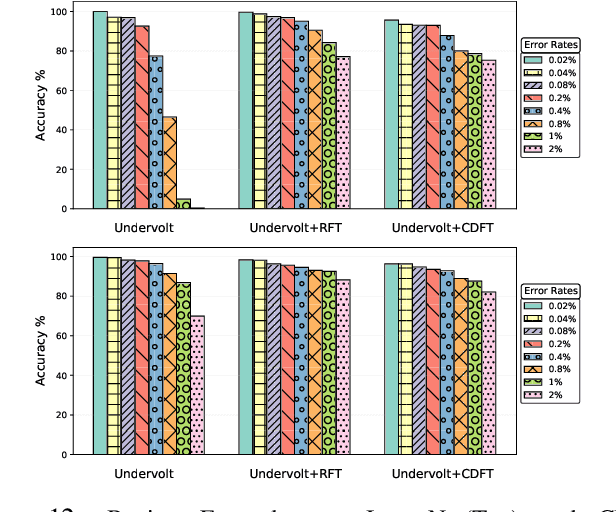
Deep neural network (DNN) classifiers are powerful tools that drive a broad spectrum of important applications, from image recognition to autonomous vehicles. Unfortunately, DNNs are known to be vulnerable to adversarial attacks that affect virtually all state-of-the-art models. These attacks make small imperceptible modifications to inputs that are sufficient to induce the DNNs to produce the wrong classification. In this paper we propose a novel, lightweight adversarial correction and/or detection mechanism for image classifiers that relies on undervolting (running a chip at a voltage that is slightly below its safe margin). We propose using controlled undervolting of the chip running the inference process in order to introduce a limited number of compute errors. We show that these errors disrupt the adversarial input in a way that can be used either to correct the classification or detect the input as adversarial. We evaluate the proposed solution in an FPGA design and through software simulation. We evaluate 10 attacks and show average detection rates of 77% and 90% on two popular DNNs.
HASI: Hardware-Accelerated Stochastic Inference, A Defense Against Adversarial Machine Learning Attacks
Jun 09, 2021
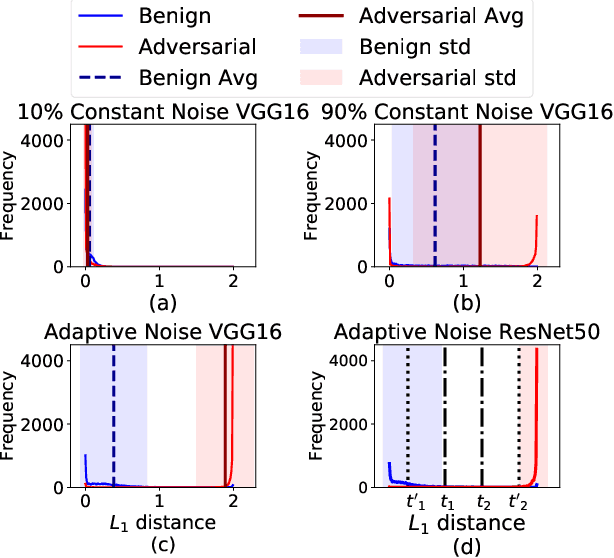

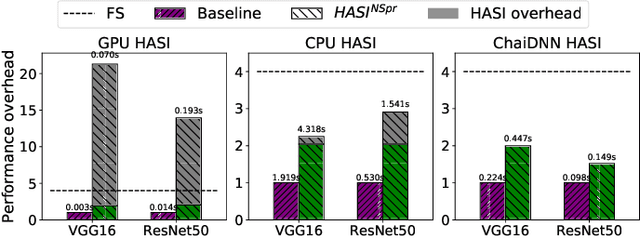
DNNs are known to be vulnerable to so-called adversarial attacks, in which inputs are carefully manipulated to induce misclassification. Existing defenses are mostly software-based and come with high overheads or other limitations. This paper presents HASI, a hardware-accelerated defense that uses a process we call stochastic inference to detect adversarial inputs. HASI carefully injects noise into the model at inference time and used the model's response to differentiate adversarial inputs from benign ones. We show an adversarial detection rate of average 87% which exceeds the detection rate of the state-of-the-art approaches, with a much lower overhead. We demonstrate a software/hardware-accelerated co-design, which reduces the performance impact of stochastic inference to 1.58X-2X relative to the unprotected baseline, compared to 14X-20X overhead for a software-only GPU implementation.