 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePulseRide: A Robotic Wheelchair for Personalized Exertion Control with Human-in-the-Loop Reinforcement Learning
Jun 05, 2025Maintaining an active lifestyle is vital for quality of life, yet challenging for wheelchair users. For instance, powered wheelchairs face increasing risks of obesity and deconditioning due to inactivity. Conversely, manual wheelchair users, who propel the wheelchair by pushing the wheelchair's handrims, often face upper extremity injuries from repetitive motions. These challenges underscore the need for a mobility system that promotes activity while minimizing injury risk. Maintaining optimal exertion during wheelchair use enhances health benefits and engagement, yet the variations in individual physiological responses complicate exertion optimization. To address this, we introduce PulseRide, a novel wheelchair system that provides personalized assistance based on each user's physiological responses, helping them maintain their physical exertion goals. Unlike conventional assistive systems focused on obstacle avoidance and navigation, PulseRide integrates real-time physiological data-such as heart rate and ECG-with wheelchair speed to deliver adaptive assistance. Using a human-in-the-loop reinforcement learning approach with Deep Q-Network algorithm (DQN), the system adjusts push assistance to keep users within a moderate activity range without under- or over-exertion. We conducted preliminary tests with 10 users on various terrains, including carpet and slate, to assess PulseRide's effectiveness. Our findings show that, for individual users, PulseRide maintains heart rates within the moderate activity zone as much as 71.7 percent longer than manual wheelchairs. Among all users, we observed an average reduction in muscle contractions of 41.86 percent, delaying fatigue onset and enhancing overall comfort and engagement. These results indicate that PulseRide offers a healthier, adaptive mobility solution, bridging the gap between passive and physically taxing mobility options.
Electronic Nose for Agricultural Grain Pest Detection, Identification, and Monitoring: A Review
May 02, 2025
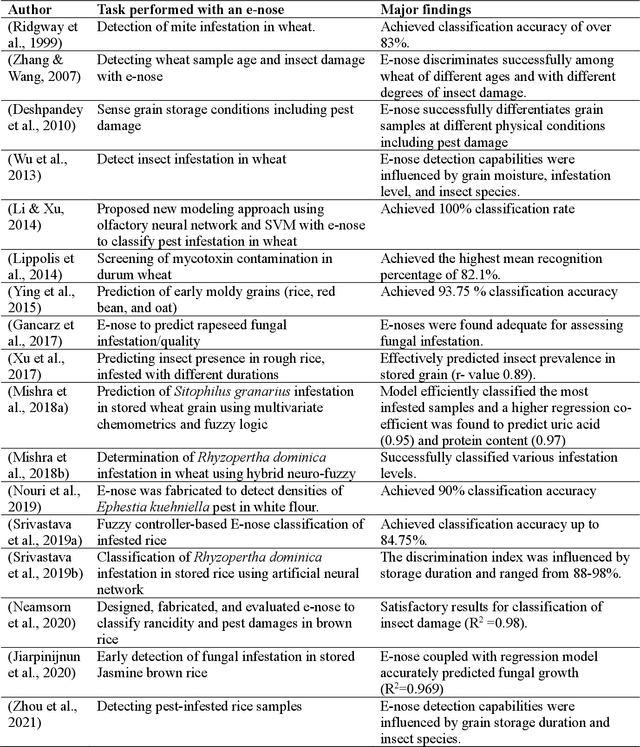


Biotic pest attacks and infestations are major causes of stored grain losses, leading to significant food and economic losses. Conventional, manual, sampling-based pest recognition methods are labor-intensive, time-consuming, costly, require expertise, and may not even detect hidden infestations. In recent years, the electronic nose (e-nose) approach has emerged as a potential alternative for agricultural grain pest recognition and monitoring. An e-nose mimics human olfactory systems by integrating a sensor array, data acquisition, and analysis for recognizing grain pests by analyzing volatile organic compounds (VOCs) emitted by grain and pests. However, well-documented, curated, and synthesized literature on the use of e-nose technology for grain pest detection is lacking. Therefore, this systematic literature review provides a comprehensive overview of the current state-of-the-art e-nose technology for agricultural grain pest monitoring. The review examines employed sensor technology, targeted pest species type, grain medium, data processing, and pattern recognition techniques. An e-nose is a promising tool that offers a rapid, low-cost, non-destructive solution for detecting, identifying, and monitoring grain pests, including microscopic and hidden insects, with good accuracy. We identified the factors that influence the e-nose performance, which include pest species, storage duration, temperature, moisture content, and pest density. The major challenges include sensor array optimization or selection, large data processing, poor repeatability, and comparability among measurements. An inexpensive and portable e-nose has the potential to help stakeholders and storage managers take timely and data-driven informed actions or decisions to reduce overall food and economic losses.
Toward Aligning Human and Robot Actions via Multi-Modal Demonstration Learning
Apr 14, 2025



Understanding action correspondence between humans and robots is essential for evaluating alignment in decision-making, particularly in human-robot collaboration and imitation learning within unstructured environments. We propose a multimodal demonstration learning framework that explicitly models human demonstrations from RGB video with robot demonstrations in voxelized RGB-D space. Focusing on the "pick and place" task from the RH20T dataset, we utilize data from 5 users across 10 diverse scenes. Our approach combines ResNet-based visual encoding for human intention modeling and a Perceiver Transformer for voxel-based robot action prediction. After 2000 training epochs, the human model reaches 71.67% accuracy, and the robot model achieves 71.8% accuracy, demonstrating the framework's potential for aligning complex, multimodal human and robot behaviors in manipulation tasks.