 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding Wikidata Qualifiers: An Analysis and Taxonomy
Mar 12, 2026This paper presents an in-depth analysis of Wikidata qualifiers, focusing on their semantics and actual usage, with the aim of developing a taxonomy that addresses the challenges of selecting appropriate qualifiers, querying the graph, and making logical inferences. The study evaluates qualifier importance based on frequency and diversity, using a modified Shannon entropy index to account for the "long tail" phenomenon. By analyzing a Wikidata dump, the top 300 qualifiers were selected and categorized into a refined taxonomy that includes contextual, epistemic/uncertainty, structural, and additional qualifiers. The taxonomy aims to guide contributors in creating and querying statements, improve qualifier recommendation systems, and enhance knowledge graph design methodologies. The results show that the taxonomy effectively covers the most important qualifiers and provides a structured approach to understanding and utilizing qualifiers in Wikidata.
Handling Wikidata Qualifiers in Reasoning
Apr 06, 2023
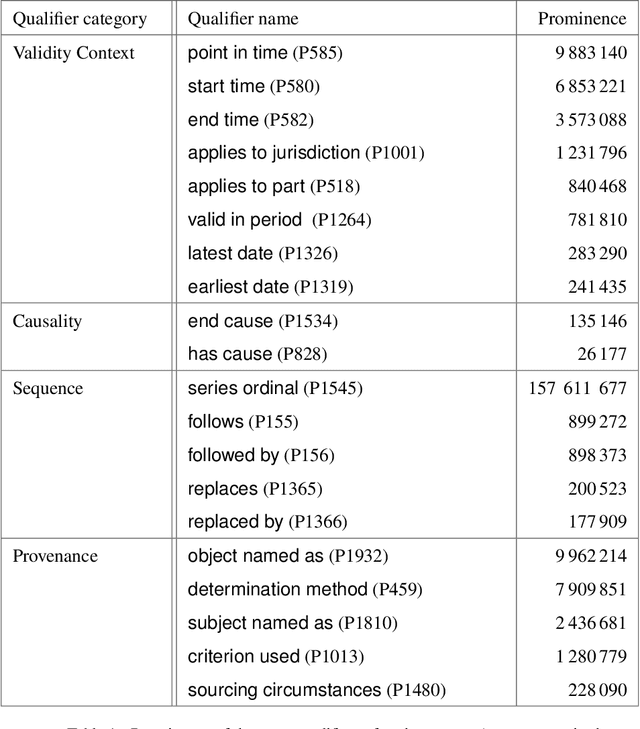


Wikidata is a knowledge graph increasingly adopted by many communities for diverse applications. Wikidata statements are annotated with qualifier-value pairs that are used to depict information, such as the validity context of the statement, its causality, provenances, etc. Handling the qualifiers in reasoning is a challenging problem. When defining inference rules (in particular, rules on ontological properties (x subclass of y, z instance of x, etc.)), one must consider the qualifiers, as most of them participate in the semantics of the statements. This poses a complex problem because a) there is a massive number of qualifiers, and b) the qualifiers of the inferred statement are often a combination of the qualifiers in the rule condition. In this work, we propose to address this problem by a) defining a categorization of the qualifiers b) formalizing the Wikidata model with a many-sorted logical language; the sorts of this language are the qualifier categories. We couple this logic with an algebraic specification that provides a means for effectively handling qualifiers in inference rules. The work supports the expression of all current Wikidata ontological properties. Finally, we discuss the methodology for practically implementing the work and present a prototype implementation.
A Semantic Model for Historical Manuscripts
Feb 02, 2018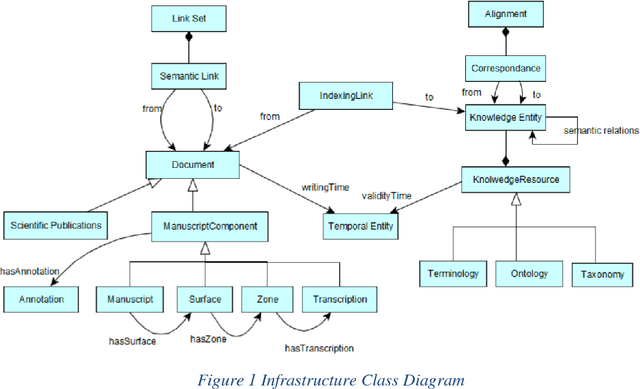
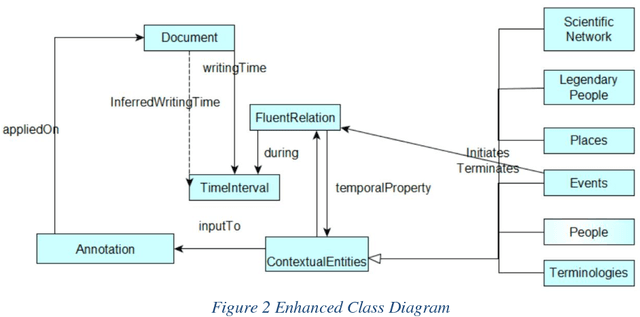
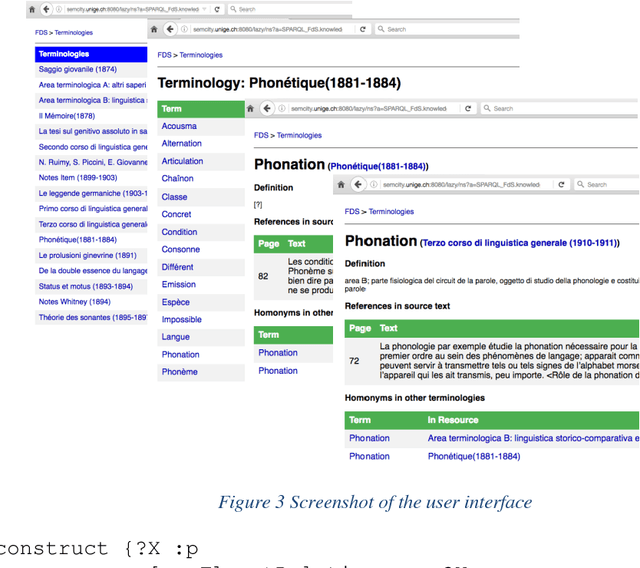
The study and publication of historical scientific manuscripts are com- plex tasks that involve, among others, the explicit representation of the text mean- ings and reasoning on temporal entities. In this paper we present the first results of an interdisciplinary project dedicated to the study of Saussure's manuscripts. These results aim to fulfill requirements elaborated with Saussurean humanists. They comprise a model for the representation of time-varying statements and time-varying domain knowledge (in particular terminologies) as well as imple- mentation techniques for the semantic indexing of manuscripts and for temporal reasoning on knowledge extracted from the manuscripts.
Un modèle pour la représentation des connaissances temporelles dans les documents historiques
Jul 25, 2017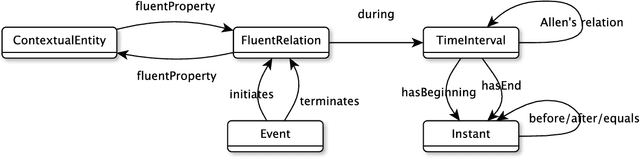
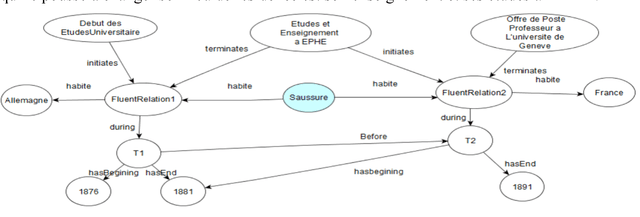
Processing and publishing the data of the historical sciences in the semantic web is an interesting challenge in which the representation of temporal aspects plays a key role. We propose in this paper a model of temporal knowledge representation adapted to work on historical documents. This model is based on the notion of fluent that is represented in RDF graphs. We show how this model allows to represent the knowledge necessary to the historians and how it can be used to reason on this knowledge using the SWRL and SPARQL languages. This model is being used in a project to digitize, study and publish the manuscripts of linguist Ferdinand de Saussure.