 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan Legislation Be Made Machine-Readable in PROLEG?
Jan 04, 2026The anticipated positive social impact of regulatory processes requires both the accuracy and efficiency of their application. Modern artificial intelligence technologies, including natural language processing and machine-assisted reasoning, hold great promise for addressing this challenge. We present a framework to address the challenge of tools for regulatory application, based on current state-of-the-art (SOTA) methods for natural language processing (large language models or LLMs) and formalization of legal reasoning (the legal representation system PROLEG). As an example, we focus on Article 6 of the European General Data Protection Regulation (GDPR). In our framework, a single LLM prompt simultaneously transforms legal text into if-then rules and a corresponding PROLEG encoding, which are then validated and refined by legal domain experts. The final output is an executable PROLEG program that can produce human-readable explanations for instances of GDPR decisions. We describe processes to support the end-to-end transformation of a segment of a regulatory document (Article 6 from GDPR), including the prompting frame to guide an LLM to "compile" natural language text to if-then rules, then to further "compile" the vetted if-then rules to PROLEG. Finally, we produce an instance that shows the PROLEG execution. We conclude by summarizing the value of this approach and note observed limitations with suggestions to further develop such technologies for capturing and deploying regulatory frameworks.
Analyzing Bias in Swiss Federal Supreme Court Judgments Using Facebook's Holistic Bias Dataset: Implications for Language Model Training
Jan 06, 2025



Natural Language Processing (NLP) is vital for computers to process and respond accurately to human language. However, biases in training data can introduce unfairness, especially in predicting legal judgment. This study focuses on analyzing biases within the Swiss Judgment Prediction Dataset (SJP-Dataset). Our aim is to ensure unbiased factual descriptions essential for fair decision making by NLP models in legal contexts. We analyze the dataset using social bias descriptors from the Holistic Bias dataset and employ advanced NLP techniques, including attention visualization, to explore the impact of dispreferred descriptors on model predictions. The study identifies biases and examines their influence on model behavior. Challenges include dataset imbalance and token limits affecting model performance.
Justifiable Artificial Intelligence: Engineering Large Language Models for Legal Applications
Nov 27, 2023In this work, I discuss how Large Language Models can be applied in the legal domain, circumventing their current drawbacks. Despite their large success and acceptance, their lack of explainability hinders legal experts to trust in their output, and this happens rightfully so. However, in this paper, I argue in favor of a new view, Justifiable Artificial Intelligence, instead of focusing on Explainable Artificial Intelligence. I discuss in this paper how gaining evidence for and against a Large Language Model's output may make their generated texts more trustworthy - or hold them accountable for misinformation.
Threshold-Based Retrieval and Textual Entailment Detection on Legal Bar Exam Questions
May 30, 2019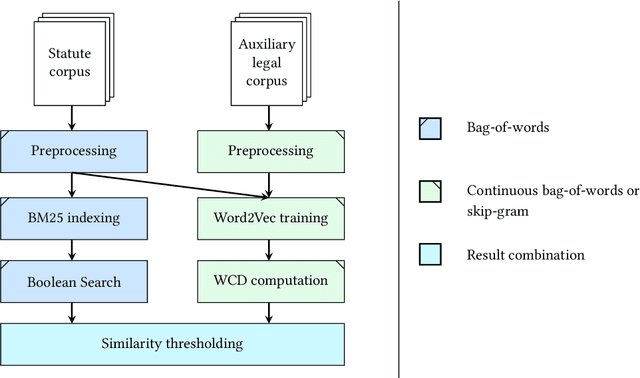
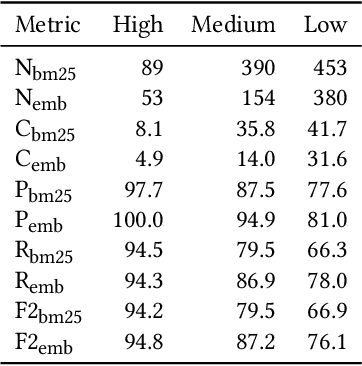
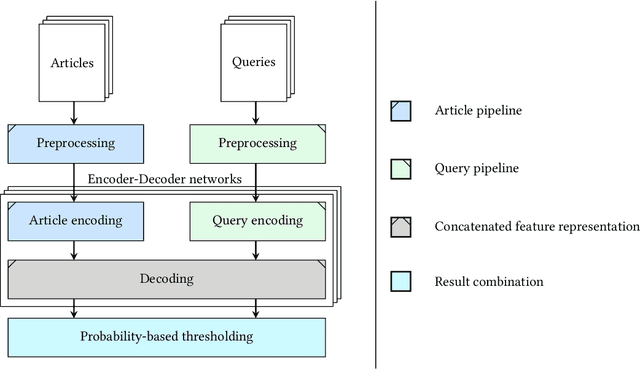
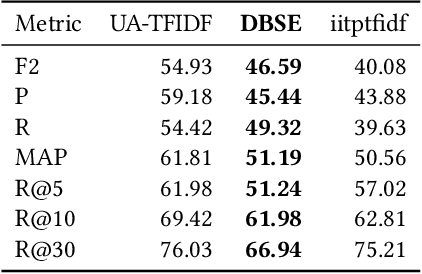
Getting an overview over the legal domain has become challenging, especially in a broad, international context. Legal question answering systems have the potential to alleviate this task by automatically retrieving relevant legal texts for a specific statement and checking whether the meaning of the statement can be inferred from the found documents. We investigate a combination of the BM25 scoring method of Elasticsearch with word embeddings trained on English translations of the German and Japanese civil law. For this, we define criteria which select a dynamic number of relevant documents according to threshold scores. Exploiting two deep learning classifiers and their respective prediction bias with a threshold-based answer inclusion criterion has shown to be beneficial for the textual entailment task, when compared to the baseline.