 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA new way of video compression via forward-referencing using deep learning
Aug 13, 2022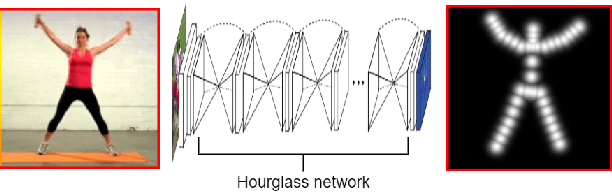
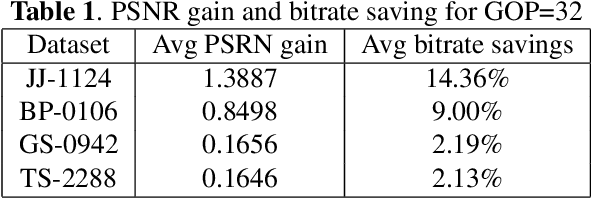

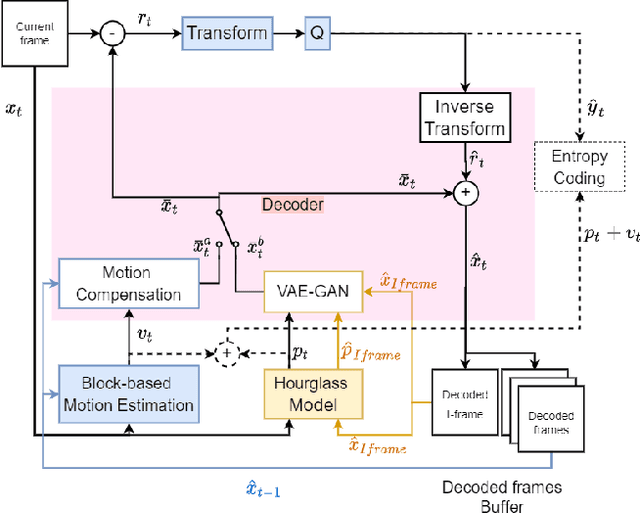
To exploit high temporal correlations in video frames of the same scene, the current frame is predicted from the already-encoded reference frames using block-based motion estimation and compensation techniques. While this approach can efficiently exploit the translation motion of the moving objects, it is susceptible to other types of affine motion and object occlusion/deocclusion. Recently, deep learning has been used to model the high-level structure of human pose in specific actions from short videos and then generate virtual frames in future time by predicting the pose using a generative adversarial network (GAN). Therefore, modelling the high-level structure of human pose is able to exploit semantic correlation by predicting human actions and determining its trajectory. Video surveillance applications will benefit as stored big surveillance data can be compressed by estimating human pose trajectories and generating future frames through semantic correlation. This paper explores a new way of video coding by modelling human pose from the already-encoded frames and using the generated frame at the current time as an additional forward-referencing frame. It is expected that the proposed approach can overcome the limitations of the traditional backward-referencing frames by predicting the blocks containing the moving objects with lower residuals. Experimental results show that the proposed approach can achieve on average up to 2.83 dB PSNR gain and 25.93\% bitrate savings for high motion video sequences