 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttackER: Towards Enhancing Cyber-Attack Attribution with a Named Entity Recognition Dataset
Aug 09, 2024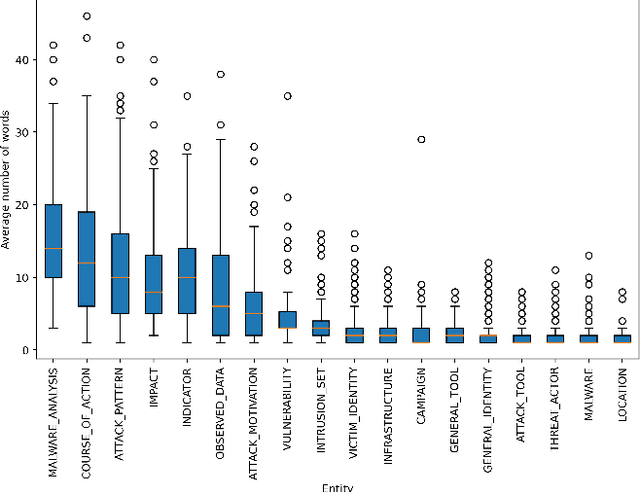

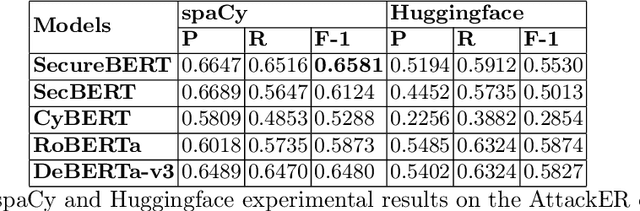
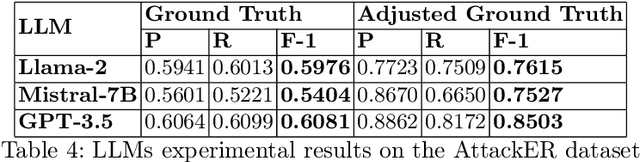
Cyber-attack attribution is an important process that allows experts to put in place attacker-oriented countermeasures and legal actions. The analysts mainly perform attribution manually, given the complex nature of this task. AI and, more specifically, Natural Language Processing (NLP) techniques can be leveraged to support cybersecurity analysts during the attribution process. However powerful these techniques are, they need to deal with the lack of datasets in the attack attribution domain. In this work, we will fill this gap and will provide, to the best of our knowledge, the first dataset on cyber-attack attribution. We designed our dataset with the primary goal of extracting attack attribution information from cybersecurity texts, utilizing named entity recognition (NER) methodologies from the field of NLP. Unlike other cybersecurity NER datasets, ours offers a rich set of annotations with contextual details, including some that span phrases and sentences. We conducted extensive experiments and applied NLP techniques to demonstrate the dataset's effectiveness for attack attribution. These experiments highlight the potential of Large Language Models (LLMs) capabilities to improve the NER tasks in cybersecurity datasets for cyber-attack attribution.
Science and Technology Ontology: A Taxonomy of Emerging Topics
May 06, 2023Ontologies play a critical role in Semantic Web technologies by providing a structured and standardized way to represent knowledge and enabling machines to understand the meaning of data. Several taxonomies and ontologies have been generated, but individuals target one domain, and only some of those have been found expensive in time and manual effort. Also, they need more coverage of unconventional topics representing a more holistic and comprehensive view of the knowledge landscape and interdisciplinary collaborations. Thus, there needs to be an ontology covering Science and Technology and facilitate multidisciplinary research by connecting topics from different fields and domains that may be related or have commonalities. To address these issues, we present an automatic Science and Technology Ontology (S&TO) that covers unconventional topics in different science and technology domains. The proposed S&TO can promote the discovery of new research areas and collaborations across disciplines. The ontology is constructed by applying BERTopic to a dataset of 393,991 scientific articles collected from Semantic Scholar from October 2021 to August 2022, covering four fields of science. Currently, S&TO includes 5,153 topics and 13,155 semantic relations. S&TO model can be updated by running BERTopic on more recent datasets