 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSmoothing Slot Attention Iterations and Recurrences
Aug 07, 2025Slot Attention (SA) and its variants lie at the heart of mainstream Object-Centric Learning (OCL). Objects in an image can be aggregated into respective slot vectors, by \textit{iteratively} refining cold-start query vectors, typically three times, via SA on image features. For video, such aggregation is \textit{recurrently} shared across frames, with queries cold-started on the first frame while transitioned from the previous frame's slots on non-first frames. However, the cold-start queries lack sample-specific cues thus hinder precise aggregation on the image or video's first frame; Also, non-first frames' queries are already sample-specific thus require transforms different from the first frame's aggregation. We address these issues for the first time with our \textit{SmoothSA}: (1) To smooth SA iterations on the image or video's first frame, we \textit{preheat} the cold-start queries with rich information of input features, via a tiny module self-distilled inside OCL; (2) To smooth SA recurrences across all video frames, we \textit{differentiate} the homogeneous transforms on the first and non-first frames, by using full and single iterations respectively. Comprehensive experiments on object discovery, recognition and downstream benchmarks validate our method's effectiveness. Further analyses intuitively illuminate how our method smooths SA iterations and recurrences. Our code is available in the supplement.
Slot Attention with Re-Initialization and Self-Distillation
Jul 31, 2025Unlike popular solutions based on dense feature maps, Object-Centric Learning (OCL) represents visual scenes as sub-symbolic object-level feature vectors, termed slots, which are highly versatile for tasks involving visual modalities. OCL typically aggregates object superpixels into slots by iteratively applying competitive cross attention, known as Slot Attention, with the slots as the query. However, once initialized, these slots are reused naively, causing redundant slots to compete with informative ones for representing objects. This often results in objects being erroneously segmented into parts. Additionally, mainstream methods derive supervision signals solely from decoding slots into the input's reconstruction, overlooking potential supervision based on internal information. To address these issues, we propose Slot Attention with re-Initialization and self-Distillation (DIAS): $\emph{i)}$ We reduce redundancy in the aggregated slots and re-initialize extra aggregation to update the remaining slots; $\emph{ii)}$ We drive the bad attention map at the first aggregation iteration to approximate the good at the last iteration to enable self-distillation. Experiments demonstrate that DIAS achieves state-of-the-art on OCL tasks like object discovery and recognition, while also improving advanced visual prediction and reasoning. Our code is available on https://github.com/Genera1Z/DIAS.
MetaSlot: Break Through the Fixed Number of Slots in Object-Centric Learning
May 27, 2025Learning object-level, structured representations is widely regarded as a key to better generalization in vision and underpins the design of next-generation Pre-trained Vision Models (PVMs). Mainstream Object-Centric Learning (OCL) methods adopt Slot Attention or its variants to iteratively aggregate objects' super-pixels into a fixed set of query feature vectors, termed slots. However, their reliance on a static slot count leads to an object being represented as multiple parts when the number of objects varies. We introduce MetaSlot, a plug-and-play Slot Attention variant that adapts to variable object counts. MetaSlot (i) maintains a codebook that holds prototypes of objects in a dataset by vector-quantizing the resulting slot representations; (ii) removes duplicate slots from the traditionally aggregated slots by quantizing them with the codebook; and (iii) injects progressively weaker noise into the Slot Attention iterations to accelerate and stabilize the aggregation. MetaSlot is a general Slot Attention variant that can be seamlessly integrated into existing OCL architectures. Across multiple public datasets and tasks--including object discovery and recognition--models equipped with MetaSlot achieve significant performance gains and markedly interpretable slot representations, compared with existing Slot Attention variants.
Vector-Quantized Vision Foundation Models for Object-Centric Learning
Feb 27, 2025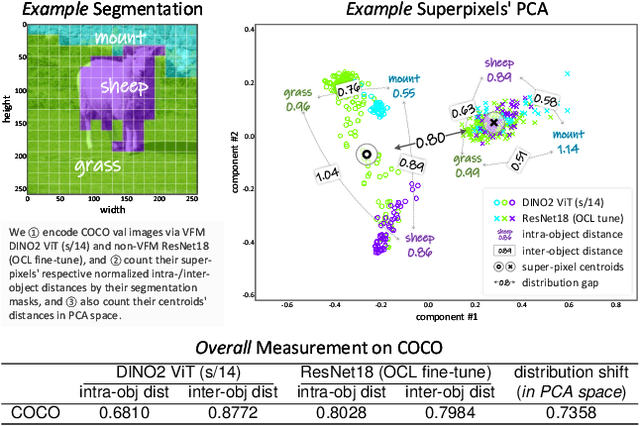
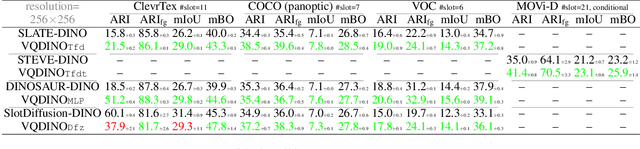
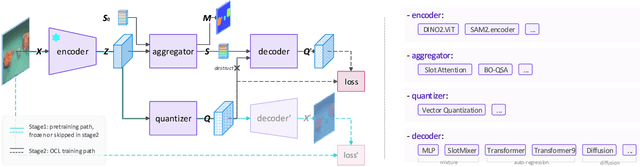
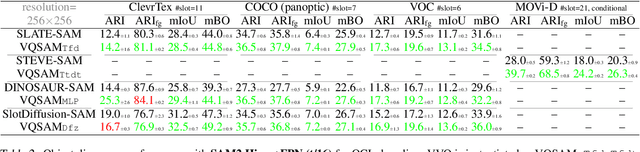
Decomposing visual scenes into objects, as humans do, facilitates modeling object relations and dynamics. Object-Centric Learning (OCL) achieves this by aggregating image or video feature maps into object-level feature vectors, known as \textit{slots}. OCL's self-supervision via reconstructing the input from slots struggles with complex textures, thus many methods employ Vision Foundation Models (VFMs) to extract feature maps with better objectness. However, using VFMs merely as feature extractors does not fully unlock their potential. We propose Vector-Quantized VFMs for OCL (VQ-VFM-OCL, or VVO), where VFM features are extracted to facilitate object-level information aggregation and further quantized to strengthen supervision in reconstruction. Our VVO unifies OCL representatives into a concise architecture. Experiments demonstrate that VVO not only outperforms mainstream methods on object discovery tasks but also benefits downstream tasks like visual prediction and reasoning. The source code is available in the supplement.
Grouped Discrete Representation for Object-Centric Learning
Nov 04, 2024



Object-Centric Learning (OCL) can discover objects in images or videos by simply reconstructing the input. For better object discovery, representative OCL methods reconstruct the input as its Variational Autoencoder (VAE) intermediate representation, which suppresses pixel noises and promotes object separability by discretizing continuous super-pixels with template features. However, treating features as units overlooks their composing attributes, thus impeding model generalization; indexing features with scalar numbers loses attribute-level similarities and differences, thus hindering model convergence. We propose \textit{Grouped Discrete Representation} (GDR) for OCL. We decompose features into combinatorial attributes via organized channel grouping, and compose these attributes into discrete representation via tuple indexes. Experiments show that our GDR improves both Transformer- and Diffusion-based OCL methods consistently on various datasets. Visualizations show that our GDR captures better object separability.
Multi-Scale Fusion for Object Representation
Oct 02, 2024

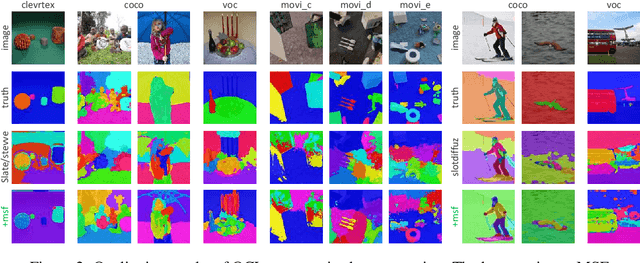

Representing images or videos as object-level feature vectors, rather than pixel-level feature maps, facilitates advanced visual tasks. Object-Centric Learning (OCL) primarily achieves this by reconstructing the input under the guidance of Variational Autoencoder (VAE) intermediate representation to drive so-called \textit{slots} to aggregate as much object information as possible. However, existing VAE guidance does not explicitly address that objects can vary in pixel sizes while models typically excel at specific pattern scales. We propose \textit{Multi-Scale Fusion} (MSF) to enhance VAE guidance for OCL training. To ensure objects of all sizes fall within VAE's comfort zone, we adopt the \textit{image pyramid}, which produces intermediate representations at multiple scales; To foster scale-invariance/variance in object super-pixels, we devise \textit{inter}/\textit{intra-scale fusion}, which augments low-quality object super-pixels of one scale with corresponding high-quality super-pixels from another scale. On standard OCL benchmarks, our technique improves mainstream methods, including state-of-the-art diffusion-based ones. The source code is available in the supplemental material.
Organized Grouped Discrete Representation for Object-Centric Learning
Sep 05, 2024Object-Centric Learning (OCL) represents dense image or video pixels as sparse object features. Representative methods utilize discrete representation composed of Variational Autoencoder (VAE) template features to suppress pixel-level information redundancy and guide object-level feature aggregation. The most recent advancement, Grouped Discrete Representation (GDR), further decomposes these template features into attributes. However, its naive channel grouping as decomposition may erroneously group channels belonging to different attributes together and discretize them as sub-optimal template attributes, which losses information and harms expressivity. We propose Organized GDR (OGDR) to organize channels belonging to the same attributes together for correct decomposition from features into attributes. In unsupervised segmentation experiments, OGDR is fully superior to GDR in augmentating classical transformer-based OCL methods; it even improves state-of-the-art diffusion-based ones. Codebook PCA and representation similarity analyses show that compared with GDR, our OGDR eliminates redundancy and preserves information better for guiding object representation learning. The source code is available in the supplementary material.
Grouped Discrete Representation Guides Object-Centric Learning
Jul 01, 2024



Similar to humans perceiving visual scenes as objects, Object-Centric Learning (OCL) can abstract dense images or videos into sparse object-level features. Transformer-based OCL handles complex textures well due to the decoding guidance of discrete representation, obtained by discretizing noisy features in image or video feature maps using template features from a codebook. However, treating features as minimal units overlooks their composing attributes, thus impeding model generalization; indexing features with natural numbers loses attribute-level commonalities and characteristics, thus diminishing heuristics for model convergence. We propose \textit{Grouped Discrete Representation} (GDR) to address these issues by grouping features into attributes and indexing them with tuple numbers. In extensive experiments across different query initializations, dataset modalities, and model architectures, GDR consistently improves convergence and generalizability. Visualizations show that our method effectively captures attribute-level information in features. The source code will be available upon acceptance.
Learnable Heterogeneous Convolution: Learning both topology and strength
Jan 13, 2023



Existing convolution techniques in artificial neural networks suffer from huge computation complexity, while the biological neural network works in a much more powerful yet efficient way. Inspired by the biological plasticity of dendritic topology and synaptic strength, our method, Learnable Heterogeneous Convolution, realizes joint learning of kernel shape and weights, which unifies existing handcrafted convolution techniques in a data-driven way. A model based on our method can converge with structural sparse weights and then be accelerated by devices of high parallelism. In the experiments, our method either reduces VGG16/19 and ResNet34/50 computation by nearly 5x on CIFAR10 and 2x on ImageNet without harming the performance, where the weights are compressed by 10x and 4x respectively; or improves the accuracy by up to 1.0% on CIFAR10 and 0.5% on ImageNet with slightly higher efficiency. The code will be available on www.github.com/Genera1Z/LearnableHeterogeneousConvolution.