 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Algorithms for High-Dimensional Convex Subspace Optimization via Strict Complementarity
Feb 08, 2022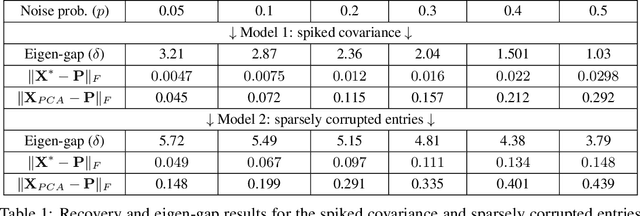

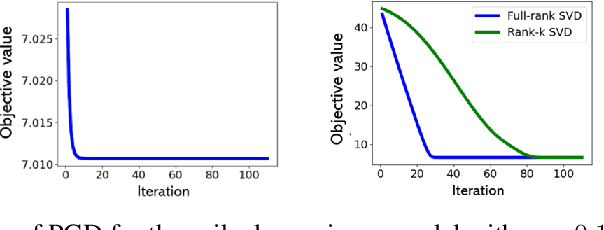
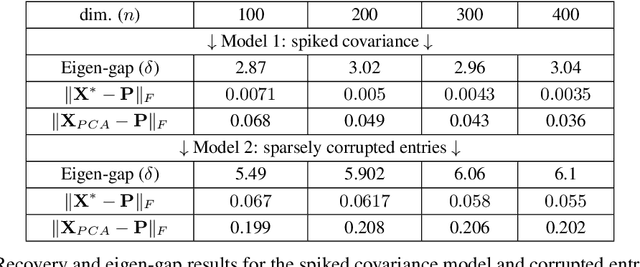
We consider optimization problems in which the goal is find a $k$-dimensional subspace of $\reals^n$, $k<<n$, which minimizes a convex and smooth loss. Such problemsgeneralize the fundamental task of principal component analysis (PCA) to include robust and sparse counterparts, and logistic PCA for binary data, among others. While this problem is not convex it admits natural algorithms with very efficient iterations and memory requirements, which is highly desired in high-dimensional regimes however, arguing about their fast convergence to a global optimal solution is difficult. On the other hand, there exists a simple convex relaxation for which convergence to the global optimum is straightforward, however corresponding algorithms are not efficient when the dimension is very large. In this work we present a natural deterministic sufficient condition so that the optimal solution to the convex relaxation is unique and is also the optimal solution to the original nonconvex problem. Mainly, we prove that under this condition, a natural highly-efficient nonconvex gradient method, which we refer to as \textit{gradient orthogonal iteration}, when initialized with a "warm-start", converges linearly for the nonconvex problem. We also establish similar results for the nonconvex projected gradient method, and the Frank-Wolfe method when applied to the convex relaxation. We conclude with empirical evidence on synthetic data which demonstrate the appeal of our approach.