 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoarse-to-Fine Multi-Scene Pose Regression with Transformers
Aug 22, 2023



Absolute camera pose regressors estimate the position and orientation of a camera given the captured image alone. Typically, a convolutional backbone with a multi-layer perceptron (MLP) head is trained using images and pose labels to embed a single reference scene at a time. Recently, this scheme was extended to learn multiple scenes by replacing the MLP head with a set of fully connected layers. In this work, we propose to learn multi-scene absolute camera pose regression with Transformers, where encoders are used to aggregate activation maps with self-attention and decoders transform latent features and scenes encoding into pose predictions. This allows our model to focus on general features that are informative for localization, while embedding multiple scenes in parallel. We extend our previous MS-Transformer approach \cite{shavit2021learning} by introducing a mixed classification-regression architecture that improves the localization accuracy. Our method is evaluated on commonly benchmark indoor and outdoor datasets and has been shown to exceed both multi-scene and state-of-the-art single-scene absolute pose regressors.
HyperPose: Camera Pose Localization using Attention Hypernetworks
Mar 05, 2023In this study, we propose the use of attention hypernetworks in camera pose localization. The dynamic nature of natural scenes, including changes in environment, perspective, and lighting, creates an inherent domain gap between the training and test sets that limits the accuracy of contemporary localization networks. To overcome this issue, we suggest a camera pose regressor that integrates a hypernetwork. During inference, the hypernetwork generates adaptive weights for the localization regression heads based on the input image, effectively reducing the domain gap. We also suggest the use of a Transformer-Encoder as the hypernetwork, instead of the common multilayer perceptron, to derive an attention hypernetwork. The proposed approach achieves superior results compared to state-of-the-art methods on contemporary datasets. To the best of our knowledge, this is the first instance of using hypernetworks in camera pose regression, as well as using Transformer-Encoders as hypernetworks. We make our code publicly available.
Paying Attention to Activation Maps in Camera Pose Regression
Apr 11, 2021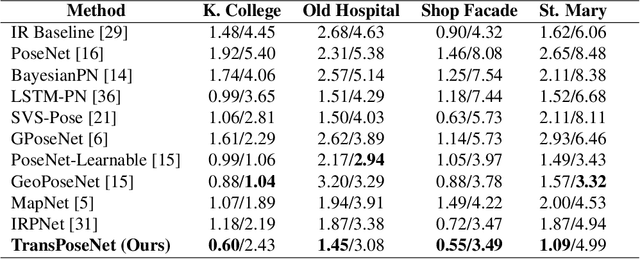
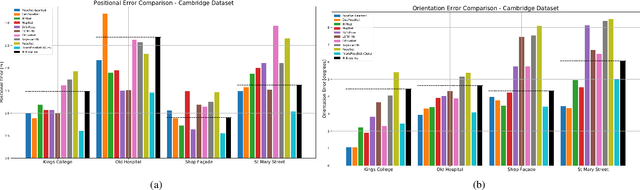
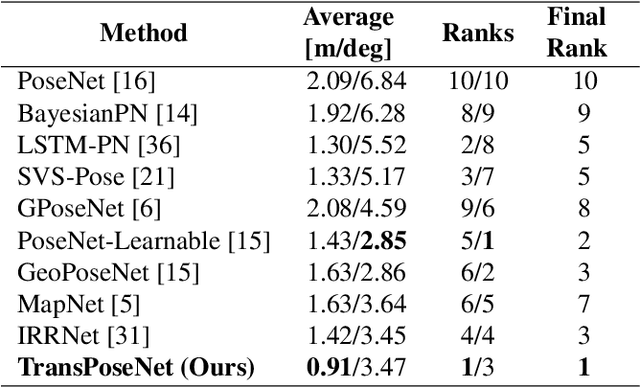
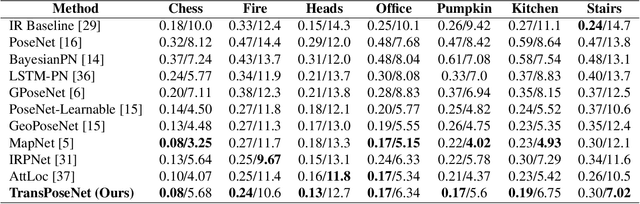
Camera pose regression methods apply a single forward pass to the query image to estimate the camera pose. As such, they offer a fast and light-weight alternative to traditional localization schemes based on image retrieval. Pose regression approaches simultaneously learn two regression tasks, aiming to jointly estimate the camera position and orientation using a single embedding vector computed by a convolutional backbone. We propose an attention-based approach for pose regression, where the convolutional activation maps are used as sequential inputs. Transformers are applied to encode the sequential activation maps as latent vectors, used for camera pose regression. This allows us to pay attention to spatially-varying deep features. Using two Transformer heads, we separately focus on the features for camera position and orientation, based on how informative they are per task. Our proposed approach is shown to compare favorably to contemporary pose regressors schemes and achieves state-of-the-art accuracy across multiple outdoor and indoor benchmarks. In particular, to the best of our knowledge, our approach is the only method to attain sub-meter average accuracy across outdoor scenes. We make our code publicly available from here.
Learning Multi-Scene Absolute Pose Regression with Transformers
Mar 21, 2021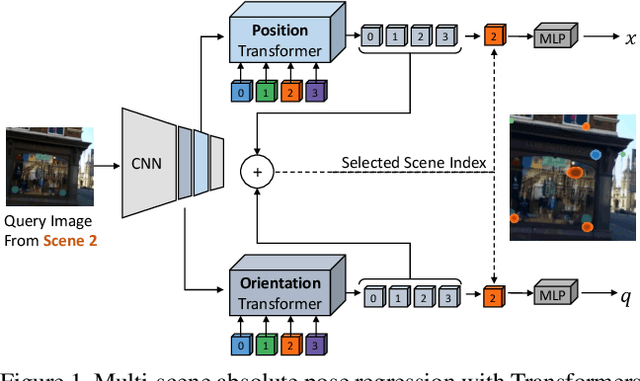
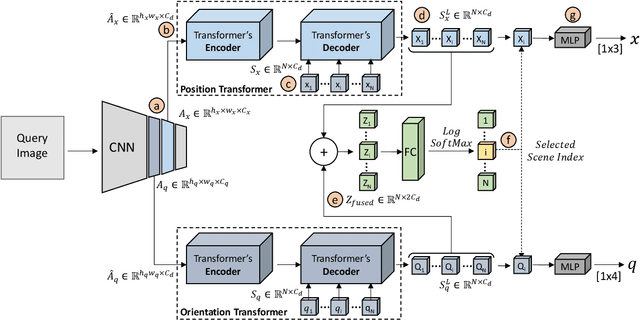
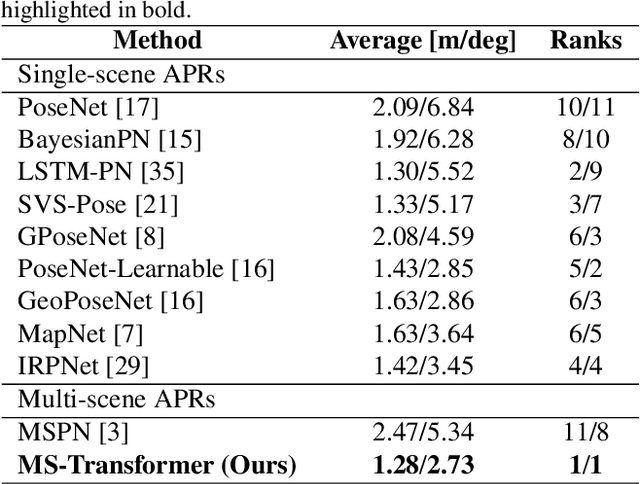

Absolute camera pose regressors estimate the position and orientation of a camera from the captured image alone. Typically, a convolutional backbone with a multi-layer perceptron head is trained with images and pose labels to embed a single reference scene at a time. Recently, this scheme was extended for learning multiple scenes by replacing the MLP head with a set of fully connected layers. In this work, we propose to learn multi-scene absolute camera pose regression with Transformers, where encoders are used to aggregate activation maps with self-attention and decoders transform latent features and scenes encoding into candidate pose predictions. This mechanism allows our model to focus on general features that are informative for localization while embedding multiple scenes in parallel. We evaluate our method on commonly benchmarked indoor and outdoor datasets and show that it surpasses both multi-scene and state-of-the-art single-scene absolute pose regressors. We make our code publicly available from here.
Do We Really Need Scene-specific Pose Encoders?
Dec 22, 2020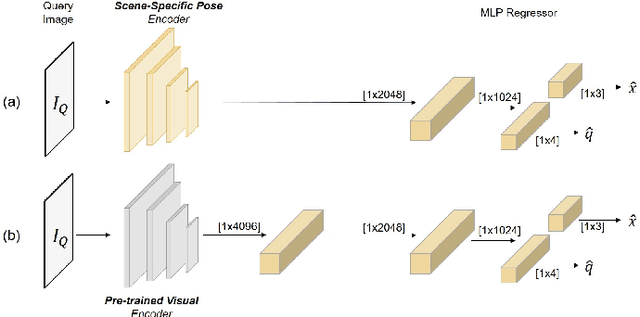
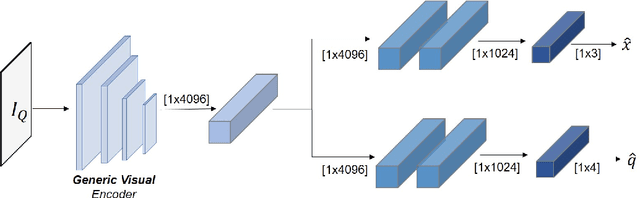
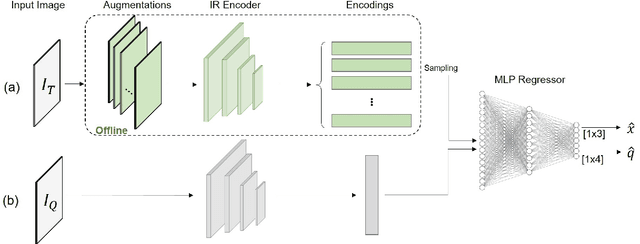
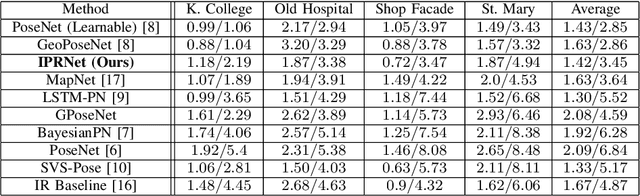
Visual pose regression models estimate the camera pose from a query image with a single forward pass. Current models learn pose encoding from an image using deep convolutional networks which are trained per scene. The resulting encoding is typically passed to a multi-layer perceptron in order to regress the pose. In this work, we propose that scene-specific pose encoders are not required for pose regression and that encodings trained for visual similarity can be used instead. In order to test our hypothesis, we take a shallow architecture of several fully connected layers and train it with pre-computed encodings from a generic image retrieval model. We find that these encodings are not only sufficient to regress the camera pose, but that, when provided to a branching fully connected architecture, a trained model can achieve competitive results and even surpass current \textit{state-of-the-art} pose regressors in some cases. Moreover, we show that for outdoor localization, the proposed architecture is the only pose regressor, to date, consistently localizing in under 2 meters and 5 degrees.
Introduction to Camera Pose Estimation with Deep Learning
Jul 16, 2019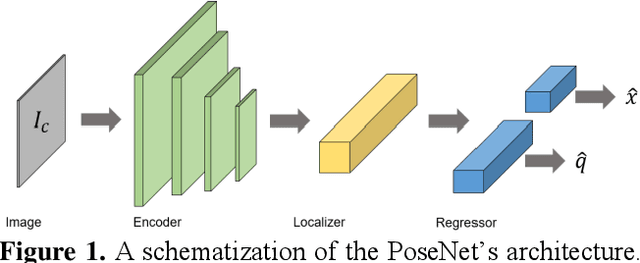
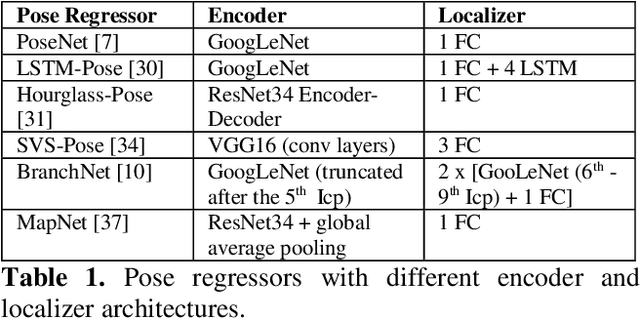
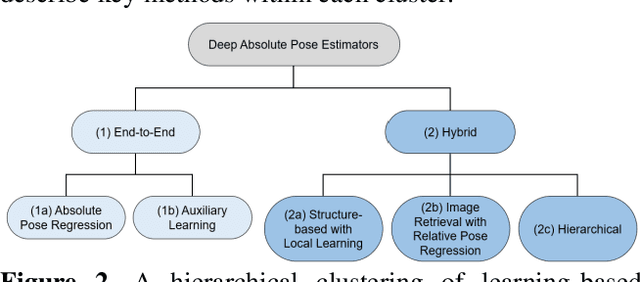
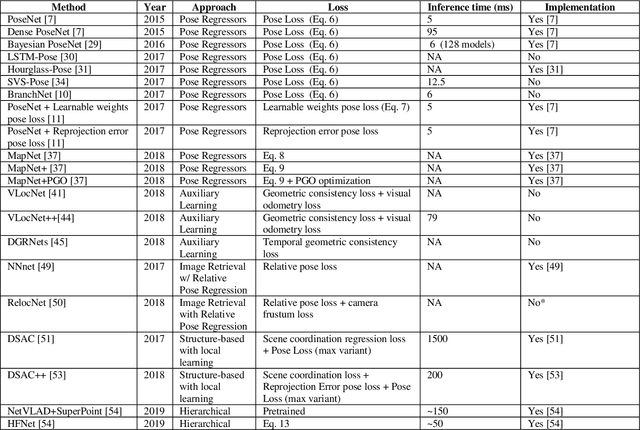
Over the last two decades, deep learning has transformed the field of computer vision. Deep convolutional networks were successfully applied to learn different vision tasks such as image classification, image segmentation, object detection and many more. By transferring the knowledge learned by deep models on large generic datasets, researchers were further able to create fine-tuned models for other more specific tasks. Recently this idea was applied for regressing the absolute camera pose from an RGB image. Although the resulting accuracy was sub-optimal, compared to classic feature-based solutions, this effort led to a surge of learning-based pose estimation methods. Here, we review deep learning approaches for camera pose estimation. We describe key methods in the field and identify trends aiming at improving the original deep pose regression solution. We further provide an extensive cross-comparison of existing learning-based pose estimators, together with practical notes on their execution for reproducibility purposes. Finally, we discuss emerging solutions and potential future research directions.