 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing Cross-Loss Influence Functions to Explain Deep Network Representations
Dec 03, 2020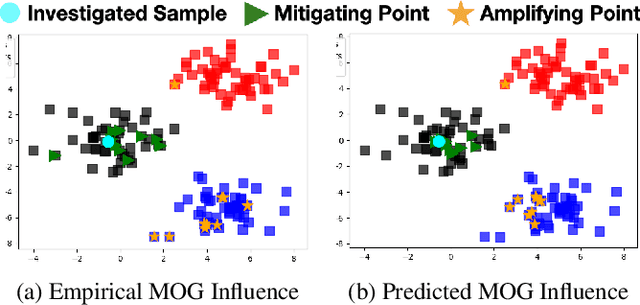



As machine learning is increasingly deployed in the real world, it is ever more vital that we understand the decision-criteria of the models we train. Recently, researchers have shown that influence functions, a statistical measure of sample impact, may be extended to approximate the effects of training samples on classification accuracy for deep neural networks. However, prior work only applies to supervised learning setups where training and testing share an objective function. Despite the rise in unsupervised learning, self-supervised learning, and model pre-training, there are currently no suitable technologies for estimating influence of deep networks that do not train and test on the same objective. To overcome this limitation, we provide the first theoretical and empirical demonstration that influence functions can be extended to handle mismatched training and testing settings. Our result enables us to compute the influence of unsupervised and self-supervised training examples with respect to a supervised test objective. We demonstrate this technique on a synthetic dataset as well as two Skip-gram language model examples to examine cluster membership and sources of unwanted bias.