 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating K-Fold Cross Validation for Transformer Based Symbolic Regression Models
Oct 29, 2024
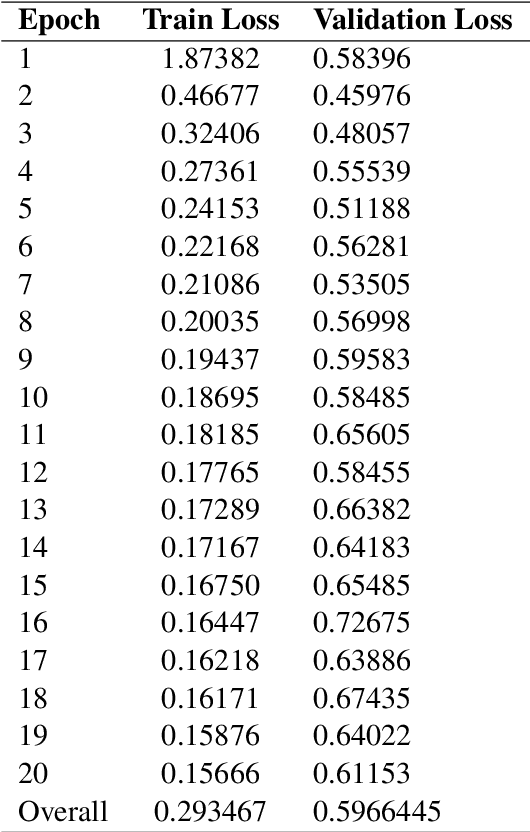


Symbolic Regression remains an NP-Hard problem, with extensive research focusing on AI models for this task. Transformer models have shown promise in Symbolic Regression, but performance suffers with smaller datasets. We propose applying k-fold cross-validation to a transformer-based symbolic regression model trained on a significantly reduced dataset (15,000 data points, down from 500,000). This technique partitions the training data into multiple subsets (folds), iteratively training on some while validating on others. Our aim is to provide an estimate of model generalization and mitigate overfitting issues associated with smaller datasets. Results show that this process improves the model's output consistency and generalization by a relative improvement in validation loss of 53.31%. Potentially enabling more efficient and accessible symbolic regression in resource-constrained environments.
Experimentation in Content Moderation using RWKV
Sep 05, 2024



This paper investigates the RWKV model's efficacy in content moderation through targeted experimentation. We introduce a novel dataset specifically designed for distillation into smaller models, enhancing content moderation practices. This comprehensive dataset encompasses images, videos, sounds, and text data that present societal challenges. Leveraging advanced Large Language Models (LLMs), we generated an extensive set of responses -- 558,958 for text and 83,625 for images -- to train and refine content moderation systems. Our core experimentation involved fine-tuning the RWKV model, capitalizing on its CPU-efficient architecture to address large-scale content moderation tasks. By highlighting the dataset's potential for knowledge distillation, this study not only demonstrates RWKV's capability in improving the accuracy and efficiency of content moderation systems but also paves the way for developing more compact, resource-efficient models in this domain. Datasets and models can be found in HuggingFace: https://huggingface.co/modrwkv