 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrediction of the final rank of Players in PUBG with the optimal number of features
Jul 01, 2021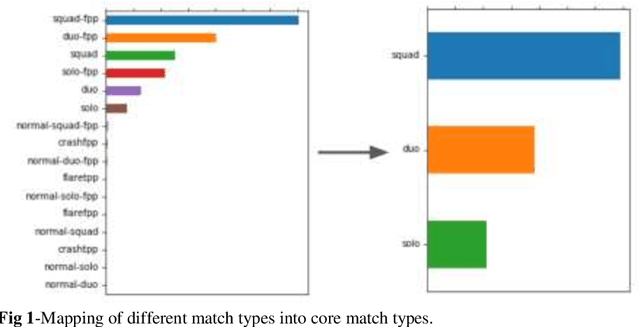

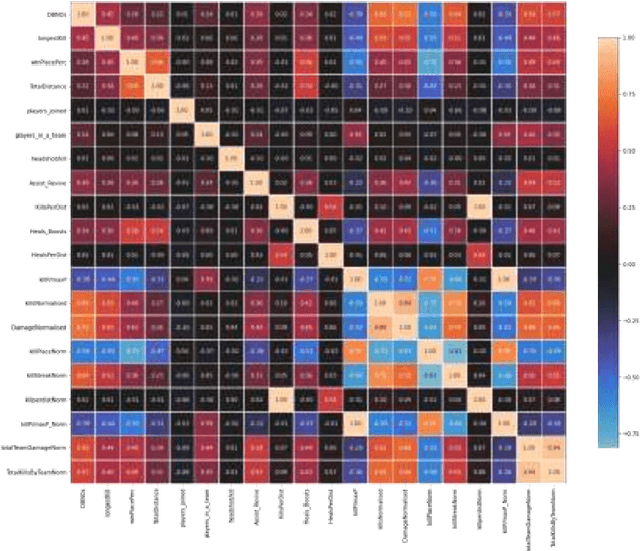

PUBG is an online video game that has become very popular among the youths in recent years. Final rank, which indicates the performance of a player, is one of the most important feature for this game. This paper focuses on predicting the final rank of the players based on their skills and abilities. In this paper we have used different machine learning algorithms to predict the final rank of the players on a dataset obtained from kaggle which has 29 features. Using the correlation heatmap,we have varied the number of features used for the model. Out of these models GBR and LGBM have given the best result with the accuracy of 91.63% and 91.26% respectively for 14 features and the accuracy of 90.54% and 90.01% for 8 features. Although the accuracy of the models with 14 features is slightly better than 8 features, the empirical time taken by 8 features is 1.4x lesser than 14 features for LGBM and 1.5x lesser for GBR. Furthermore, reducing the number of features any more significantly hampers the performance of all the ML models. Therefore, we conclude that 8 is the optimal number of features that can be used to predict the final rank of a player in PUBG with high accuracy and low run-time.
A machine learning based heuristic to predict the efficacy of online sale
May 10, 2020


It is difficult to decide upon the efficacy of an online sale simply from the discount offered on commodities. Different features have different influence on the price of a product which must be taken into consideration when determining the significance of a discount. In this paper we have proposed a machine learning based heuristic to quantify the \textit{"significance"} of the discount offered on any commodity. Our proposed technique can quantify the significance of the discount based on features and the original price, and hence can guide a buyer during a sale season by predicting the efficacy of the sale. We have applied this technique on the Flipkart Summer Sale dataset using Support Vector Machine, which predicts the efficacy of the sale with an accuracy of 91.11\%. Our result shows that very few mobile phones have a significant discount during the Flipkart Summer Sale.
An Empirical Study of Incremental Learning in Neural Network with Noisy Training Set
May 07, 2020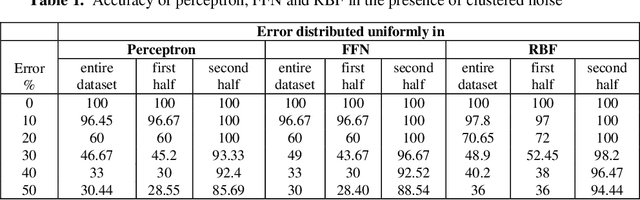
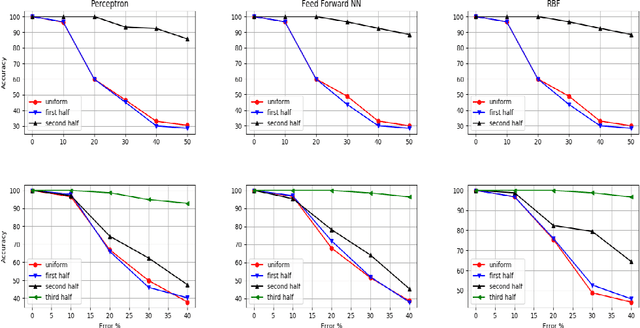
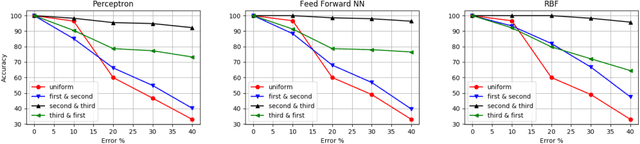
The notion of incremental learning is to train an ANN algorithm in stages, as and when newer training data arrives. Incremental learning is becoming widespread in recent times with the advent of deep learning. Noise in the training data reduces the accuracy of the algorithm. In this paper, we make an empirical study of the effect of noise in the training phase. We numerically show that the accuracy of the algorithm is dependent more on the location of the error than the percentage of error. Using Perceptron, Feed Forward Neural Network and Radial Basis Function Neural Network, we show that for the same percentage of error, the accuracy of the algorithm significantly varies with the location of error. Furthermore, our results show that the dependence of the accuracy with the location of error is independent of the algorithm. However, the slope of the degradation curve decreases with more sophisticated algorithms