 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Multimodal Large Language Models Support Access to Visual Information: A Diary Study With Blind and Low Vision People
Feb 13, 2026Multimodal large language models (MLLMs) are changing how Blind and Low Vision (BLV) people access visual information in their daily lives. Unlike traditional visual interpretation tools that provide access through captions and OCR (text recognition through camera input), MLLM-enabled applications support access through conversational assistance, where users can ask questions to obtain goal-relevant details. However, evidence about their performance in the real-world and their implications for BLV people's everyday life remain limited. To address this, we conducted a two-week diary study, where we captured 20 BLV participants' use of an MLLM-enabled visual interpretation application. Although participants rated the visual interpretations of the application as "somewhat trustworthy" (mean=3.76 out of 5, max=very trustworthy) and "somewhat satisfying" (mean=4.13 out of 5, max=very satisfying), the AI often produced incorrect answers (22.2%) or abstained (10.8%) from responding to follow-up requests. Our work demonstrates that MLLMs can improve the accuracy of descriptive visual interpretations, but that supporting everyday use also depends on the "visual assistant" skill -- a set of behaviors for providing goal-directed, reliable assistance. We conclude by proposing the "visual assistant" skill and practical guidelines to help future MLLM-enabled visual interpretation applications better support BLV people's access to visual information.
Towards Understanding the Use of MLLM-Enabled Applications for Visual Interpretation by Blind and Low Vision People
Mar 07, 2025
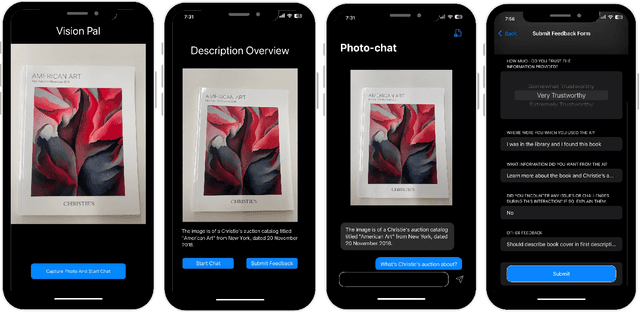

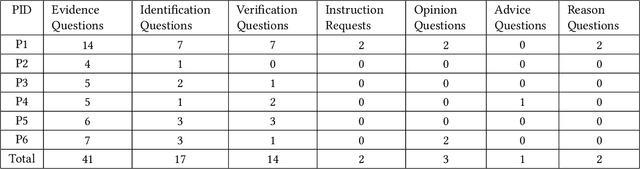
Blind and Low Vision (BLV) people have adopted AI-powered visual interpretation applications to address their daily needs. While these applications have been helpful, prior work has found that users remain unsatisfied by their frequent errors. Recently, multimodal large language models (MLLMs) have been integrated into visual interpretation applications, and they show promise for more descriptive visual interpretations. However, it is still unknown how this advancement has changed people's use of these applications. To address this gap, we conducted a two-week diary study in which 20 BLV people used an MLLM-enabled visual interpretation application we developed, and we collected 553 entries. In this paper, we report a preliminary analysis of 60 diary entries from 6 participants. We found that participants considered the application's visual interpretations trustworthy (mean 3.75 out of 5) and satisfying (mean 4.15 out of 5). Moreover, participants trusted our application in high-stakes scenarios, such as receiving medical dosage advice. We discuss our plan to complete our analysis to inform the design of future MLLM-enabled visual interpretation systems.