 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient-VDVAE: Less is more
Mar 25, 2022


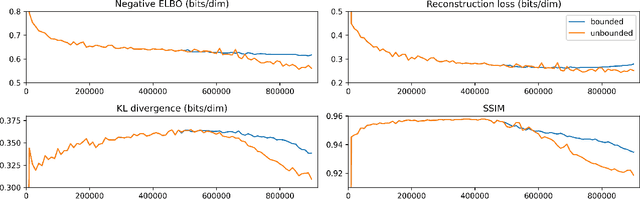
Hierarchical VAEs have emerged in recent years as a reliable option for maximum likelihood estimation. However, instability issues and demanding computational requirements have hindered research progress in the area. We present simple modifications to the Very Deep VAE to make it converge up to $2.6\times$ faster, save up to $20\times$ in memory load and improve stability during training. Despite these changes, our models achieve comparable or better negative log-likelihood performance than current state-of-the-art models on all $7$ commonly used image datasets we evaluated on. We also make an argument against using 5-bit benchmarks as a way to measure hierarchical VAE's performance due to undesirable biases caused by the 5-bit quantization. Additionally, we empirically demonstrate that roughly $3\%$ of the hierarchical VAE's latent space dimensions is sufficient to encode most of the image information, without loss of performance, opening up the doors to efficiently leverage the hierarchical VAEs' latent space in downstream tasks. We release our source code and models at https://github.com/Rayhane-mamah/Efficient-VDVAE .
NWT: Towards natural audio-to-video generation with representation learning
Jun 08, 2021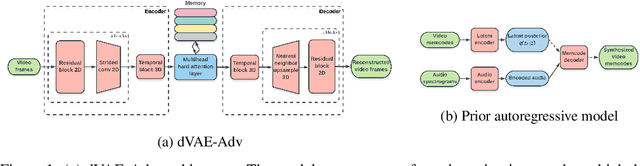


In this work we introduce NWT, an expressive speech-to-video model. Unlike approaches that use domain-specific intermediate representations such as pose keypoints, NWT learns its own latent representations, with minimal assumptions about the audio and video content. To this end, we propose a novel discrete variational autoencoder with adversarial loss, dVAE-Adv, which learns a new discrete latent representation we call Memcodes. Memcodes are straightforward to implement, require no additional loss terms, are stable to train compared with other approaches, and show evidence of interpretability. To predict on the Memcode space, we use an autoregressive encoder-decoder model conditioned on audio. Additionally, our model can control latent attributes in the generated video that are not annotated in the data. We train NWT on clips from HBO's Last Week Tonight with John Oliver. NWT consistently scores above other approaches in Mean Opinion Score (MOS) on tests of overall video naturalness, facial naturalness and expressiveness, and lipsync quality. This work sets a strong baseline for generalized audio-to-video synthesis. Samples are available at https://next-week-tonight.github.io/NWT/.