 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimizing TinyML: The Impact of Reduced Data Acquisition Rates for Time Series Classification on Microcontrollers
Sep 17, 2024
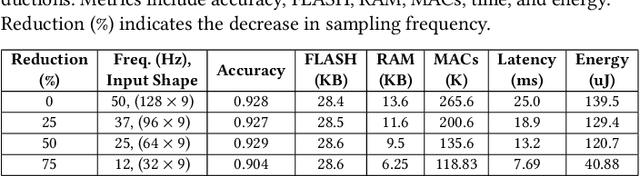
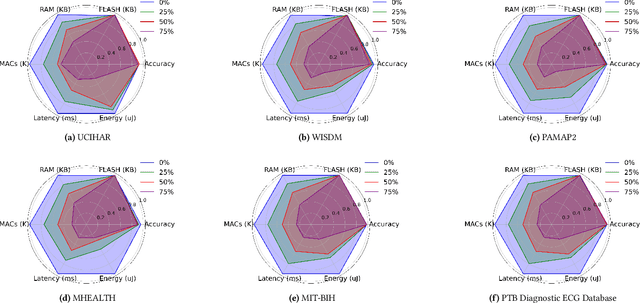
Tiny Machine Learning (TinyML) enables efficient, lowcost, and privacy preserving machine learning inference directly on microcontroller units (MCUs) connected to sensors. Optimizing models for these constrained environments is crucial. This paper investigates how reducing data acquisition rates affects TinyML models for time series classification, focusing on resource-constrained, battery operated IoT devices. By lowering data sampling frequency, we aim to reduce computational demands RAM usage, energy consumption, latency, and MAC operations by approximately fourfold while maintaining similar classification accuracies. Our experiments with six benchmark datasets (UCIHAR, WISDM, PAMAP2, MHEALTH, MITBIH, and PTB) showed that reducing data acquisition rates significantly cut energy consumption and computational load, with minimal accuracy loss. For example, a 75\% reduction in acquisition rate for MITBIH and PTB datasets led to a 60\% decrease in RAM usage, 75\% reduction in MAC operations, 74\% decrease in latency, and 70\% reduction in energy consumption, without accuracy loss. These results offer valuable insights for deploying efficient TinyML models in constrained environments.
TinyTNAS: GPU-Free, Time-Bound, Hardware-Aware Neural Architecture Search for TinyML Time Series Classification
Aug 29, 2024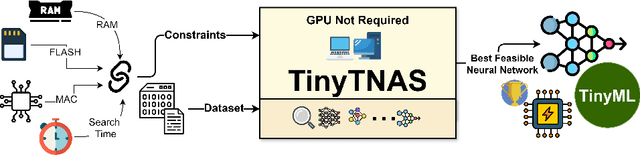
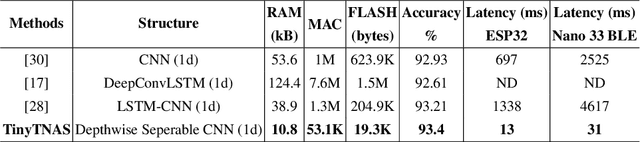
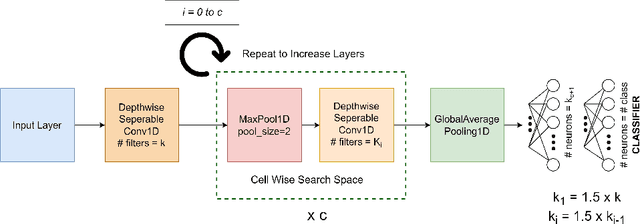
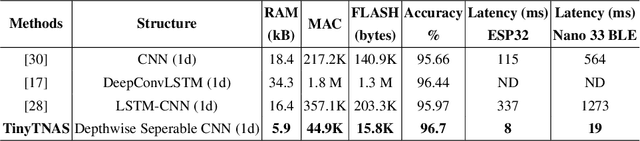
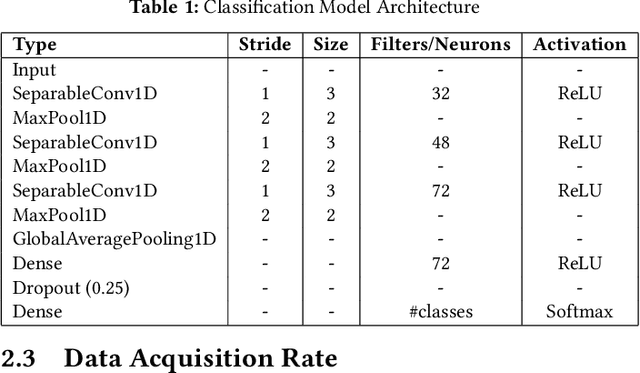
In this work, we present TinyTNAS, a novel hardware-aware multi-objective Neural Architecture Search (NAS) tool specifically designed for TinyML time series classification. Unlike traditional NAS methods that rely on GPU capabilities, TinyTNAS operates efficiently on CPUs, making it accessible for a broader range of applications. Users can define constraints on RAM, FLASH, and MAC operations to discover optimal neural network architectures within these parameters. Additionally, the tool allows for time-bound searches, ensuring the best possible model is found within a user-specified duration. By experimenting with benchmark dataset UCI HAR, PAMAP2, WISDM, MIT BIH, and PTB Diagnostic ECG Databas TinyTNAS demonstrates state-of-the-art accuracy with significant reductions in RAM, FLASH, MAC usage, and latency. For example, on the UCI HAR dataset, TinyTNAS achieves a 12x reduction in RAM usage, a 144x reduction in MAC operations, and a 78x reduction in FLASH memory while maintaining superior accuracy and reducing latency by 149x. Similarly, on the PAMAP2 and WISDM datasets, it achieves a 6x reduction in RAM usage, a 40x reduction in MAC operations, an 83x reduction in FLASH, and a 67x reduction in latency, all while maintaining superior accuracy. Notably, the search process completes within 10 minutes in a CPU environment. These results highlight TinyTNAS's capability to optimize neural network architectures effectively for resource-constrained TinyML applications, ensuring both efficiency and high performance. The code for TinyTNAS is available at the GitHub repository and can be accessed at https://github.com/BidyutSaha/TinyTNAS.git.