 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Sequential Model Performance with Squared Sigmoid TanH (SST) Activation Under Data Constraints
Feb 14, 2024Activation functions enable neural networks to learn complex representations by introducing non-linearities. While feedforward models commonly use rectified linear units, sequential models like recurrent neural networks, long short-term memory (LSTMs) and gated recurrent units (GRUs) still rely on Sigmoid and TanH activation functions. However, these classical activation functions often struggle to model sparse patterns when trained on small sequential datasets to effectively capture temporal dependencies. To address this limitation, we propose squared Sigmoid TanH (SST) activation specifically tailored to enhance the learning capability of sequential models under data constraints. SST applies mathematical squaring to amplify differences between strong and weak activations as signals propagate over time, facilitating improved gradient flow and information filtering. We evaluate SST-powered LSTMs and GRUs for diverse applications, such as sign language recognition, regression, and time-series classification tasks, where the dataset is limited. Our experiments demonstrate that SST models consistently outperform RNN-based models with baseline activations, exhibiting improved test accuracy.
APALU: A Trainable, Adaptive Activation Function for Deep Learning Networks
Feb 13, 2024
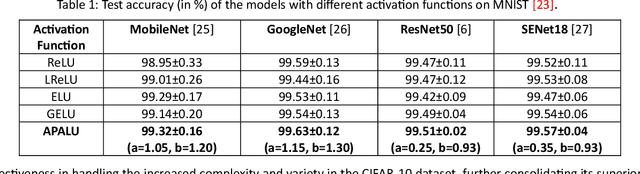
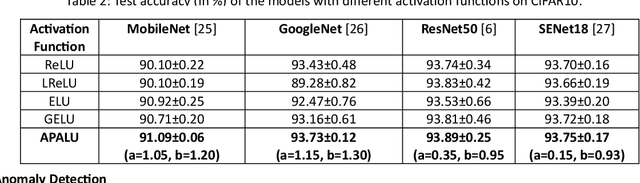

Activation function is a pivotal component of deep learning, facilitating the extraction of intricate data patterns. While classical activation functions like ReLU and its variants are extensively utilized, their static nature and simplicity, despite being advantageous, often limit their effectiveness in specialized tasks. The trainable activation functions also struggle sometimes to adapt to the unique characteristics of the data. Addressing these limitations, we introduce a novel trainable activation function, adaptive piecewise approximated activation linear unit (APALU), to enhance the learning performance of deep learning across a broad range of tasks. It presents a unique set of features that enable it to maintain stability and efficiency in the learning process while adapting to complex data representations. Experiments reveal significant improvements over widely used activation functions for different tasks. In image classification, APALU increases MobileNet and GoogleNet accuracy by 0.37% and 0.04%, respectively, on the CIFAR10 dataset. In anomaly detection, it improves the average area under the curve of One-CLASS Deep SVDD by 0.8% on the MNIST dataset, 1.81% and 1.11% improvements with DifferNet, and knowledge distillation, respectively, on the MVTech dataset. Notably, APALU achieves 100% accuracy on a sign language recognition task with a limited dataset. For regression tasks, APALU enhances the performance of deep neural networks and recurrent neural networks on different datasets. These improvements highlight the robustness and adaptability of APALU across diverse deep-learning applications.