 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Review of YOLOv12: Attention-Based Enhancements vs. Previous Versions
Apr 16, 2025The YOLO (You Only Look Once) series has been a leading framework in real-time object detection, consistently improving the balance between speed and accuracy. However, integrating attention mechanisms into YOLO has been challenging due to their high computational overhead. YOLOv12 introduces a novel approach that successfully incorporates attention-based enhancements while preserving real-time performance. This paper provides a comprehensive review of YOLOv12's architectural innovations, including Area Attention for computationally efficient self-attention, Residual Efficient Layer Aggregation Networks for improved feature aggregation, and FlashAttention for optimized memory access. Additionally, we benchmark YOLOv12 against prior YOLO versions and competing object detectors, analyzing its improvements in accuracy, inference speed, and computational efficiency. Through this analysis, we demonstrate how YOLOv12 advances real-time object detection by refining the latency-accuracy trade-off and optimizing computational resources.
PV-faultNet: Optimized CNN Architecture to detect defects resulting efficient PV production
Nov 05, 2024



The global shift towards renewable energy has pushed PV cell manufacturing as a pivotal point as they are the fundamental building block of green energy. However, the manufacturing process is complex enough to lose its purpose due to probable defects experienced during the time impacting the overall efficiency. However, at the moment, manual inspection is being conducted to detect the defects that can cause bias, leading to time and cost inefficiency. Even if automated solutions have also been proposed, most of them are resource-intensive, proving ineffective in production environments. In that context, this study presents PV-faultNet, a lightweight Convolutional Neural Network (CNN) architecture optimized for efficient and real-time defect detection in photovoltaic (PV) cells, designed to be deployable on resource-limited production devices. Addressing computational challenges in industrial PV manufacturing environments, the model includes only 2.92 million parameters, significantly reducing processing demands without sacrificing accuracy. Comprehensive data augmentation techniques were implemented to tackle data scarcity, thus enhancing model generalization and maintaining a balance between precision and recall. The proposed model achieved high performance with 91\% precision, 89\% recall, and a 90\% F1 score, demonstrating its effectiveness for scalable quality control in PV production.
YOLOv11: An Overview of the Key Architectural Enhancements
Oct 23, 2024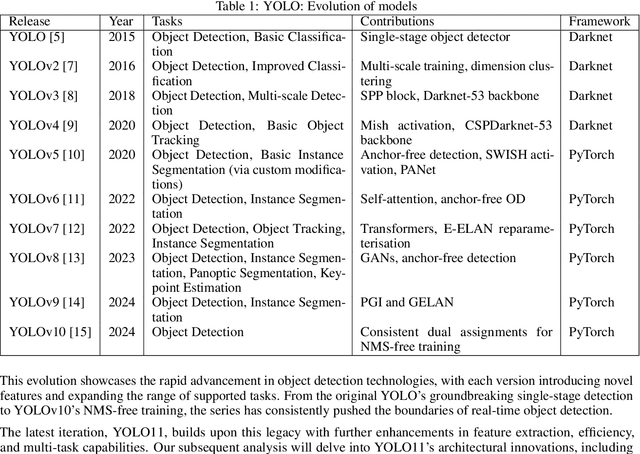
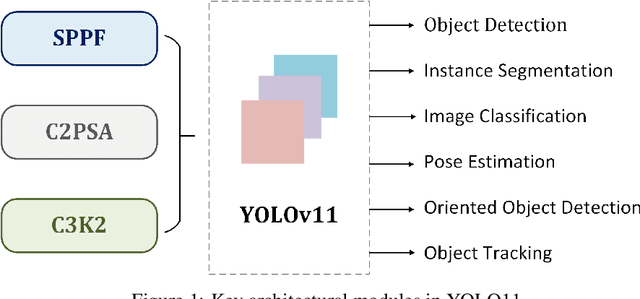

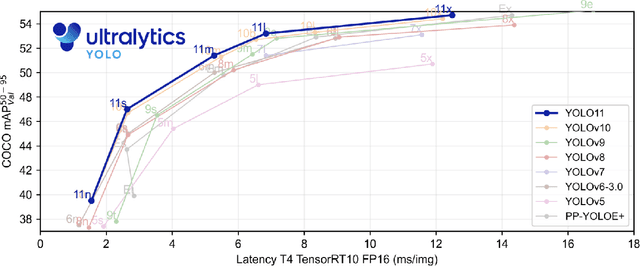
This study presents an architectural analysis of YOLOv11, the latest iteration in the YOLO (You Only Look Once) series of object detection models. We examine the models architectural innovations, including the introduction of the C3k2 (Cross Stage Partial with kernel size 2) block, SPPF (Spatial Pyramid Pooling - Fast), and C2PSA (Convolutional block with Parallel Spatial Attention) components, which contribute in improving the models performance in several ways such as enhanced feature extraction. The paper explores YOLOv11's expanded capabilities across various computer vision tasks, including object detection, instance segmentation, pose estimation, and oriented object detection (OBB). We review the model's performance improvements in terms of mean Average Precision (mAP) and computational efficiency compared to its predecessors, with a focus on the trade-off between parameter count and accuracy. Additionally, the study discusses YOLOv11's versatility across different model sizes, from nano to extra-large, catering to diverse application needs from edge devices to high-performance computing environments. Our research provides insights into YOLOv11's position within the broader landscape of object detection and its potential impact on real-time computer vision applications.
What is YOLOv5: A deep look into the internal features of the popular object detector
Jul 30, 2024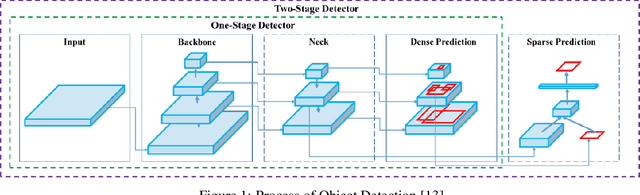
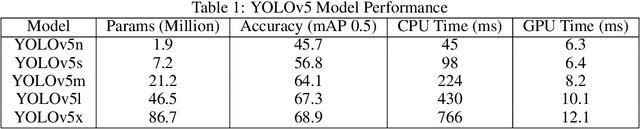
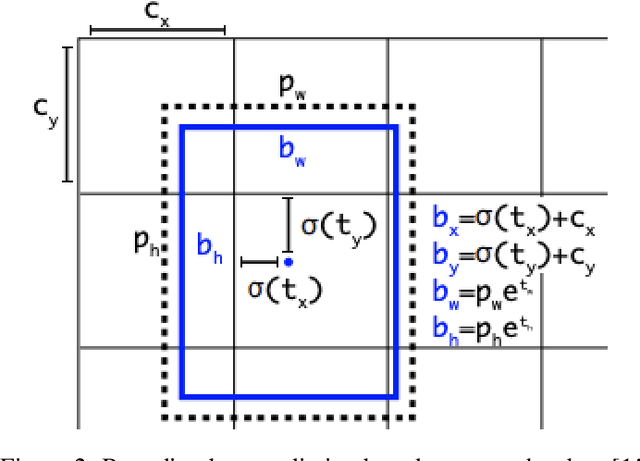

This study presents a comprehensive analysis of the YOLOv5 object detection model, examining its architecture, training methodologies, and performance. Key components, including the Cross Stage Partial backbone and Path Aggregation-Network, are explored in detail. The paper reviews the model's performance across various metrics and hardware platforms. Additionally, the study discusses the transition from Darknet to PyTorch and its impact on model development. Overall, this research provides insights into YOLOv5's capabilities and its position within the broader landscape of object detection and why it is a popular choice for constrained edge deployment scenarios.