 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFully Convolutional Network for Removing DCT Artefacts From Images
Jul 08, 2019
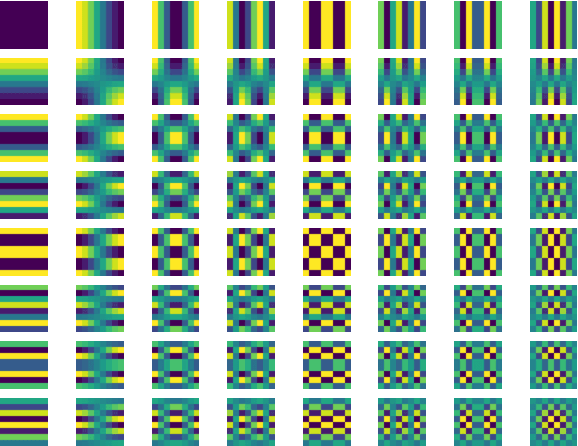
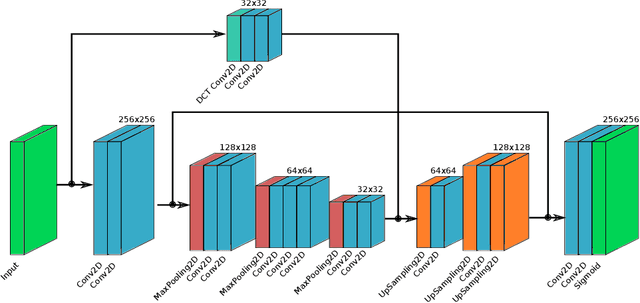
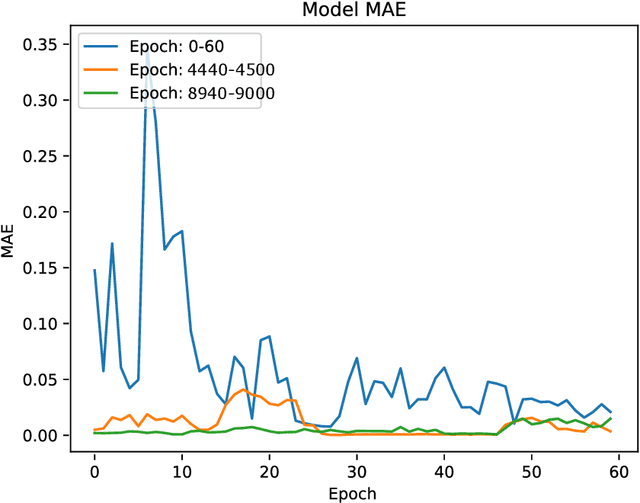
Deep learning methods achieve excellent results in image transformations as well as image noise reduction or super-resolution methods. Based on these solutions, we present a deep-learning method of block reconstruction of images compressed with the JPEG format. Images compressed with the discrete cosine transform (DCT) contain visible artefacts in the form of blocks, which in some cases spoil the aesthetics of the image mostly on the edges of the contrasting elements. This is unavoidable, and the discernibility of the block artefacts can be adjusted by the degree of image compression, which profoundly affects the output image size. We use a fully convolutional network which operates directly on 8x8-pixel blocks in the same way as the JPEG encoder. Thanks to that, we do not modify the input image; we only divide it into separately processed blocks. The purpose of our neural model is to modify the pixels in the blocks to reduce artefact visibility %against the background of the neighbouring image and to recreate the original pattern of the image distorted by the DCT transform. We trained our model on a dataset created from vector images transformed to the JPEG and PNG formats, as the input and output data, respectively.
Bag-of-Features Image Indexing and Classification in Microsoft SQL Server Relational Database
Jun 26, 2015



This paper presents a novel relational database architecture aimed to visual objects classification and retrieval. The framework is based on the bag-of-features image representation model combined with the Support Vector Machine classification and is integrated in a Microsoft SQL Server database.
Fast Dictionary Matching for Content-based Image Retrieval
Apr 26, 2015

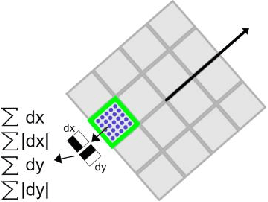
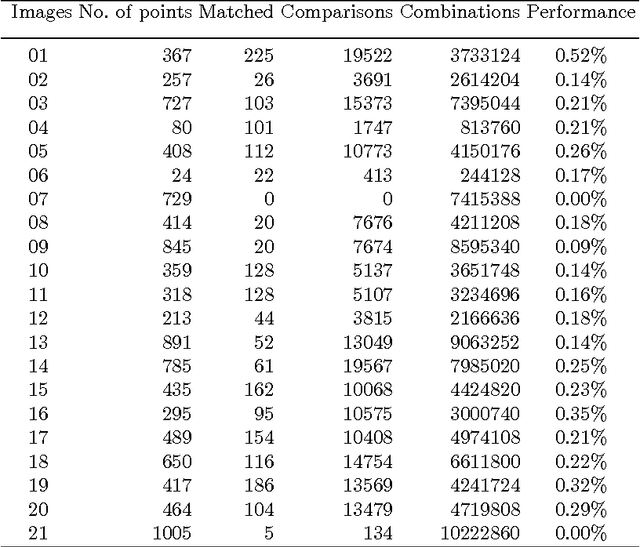
This paper describes a method for searching for common sets of descriptors between collections of images. The presented method operates on local interest keypoints, which are generated using the SURF algorithm. The use of a dictionary of descriptors allowed achieving good performance of the content-based image retrieval. The method can be used to initially determine a set of similar pairs of keypoints between images. For this purpose, we use a certain level of tolerance between values of descriptors, as values of feature descriptors are almost never equal but similar between different images. After that, the method compares the structure of rotation and location of interest points in one image with the point structure in other images. Thus, we were able to find similar areas in images and determine the level of similarity between them, even when images contain different scenes.