 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowledge Squeezed Adversarial Network Compression
Apr 25, 2019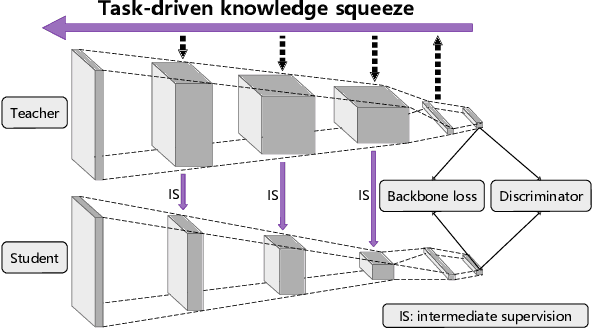
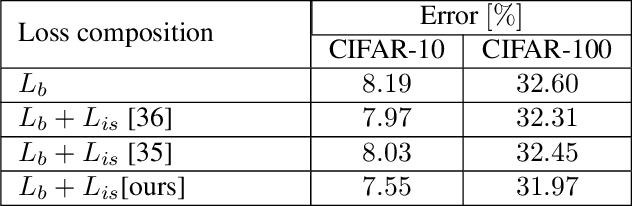
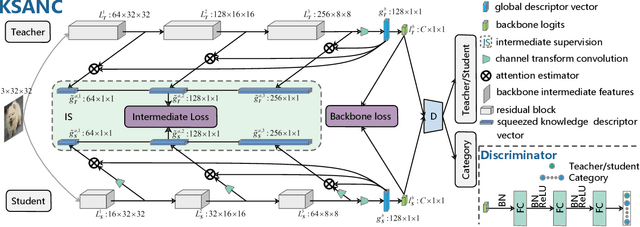
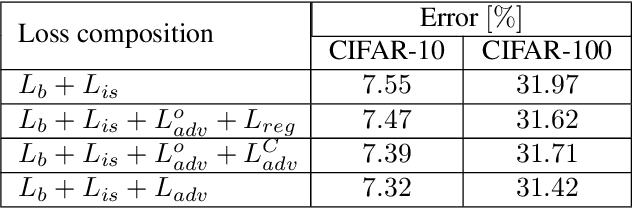
Deep network compression has been achieved notable progress via knowledge distillation, where a teacher-student learning manner is adopted by using predetermined loss. Recently, more focuses have been transferred to employ the adversarial training to minimize the discrepancy between distributions of output from two networks. However, they always emphasize on result-oriented learning while neglecting the scheme of process-oriented learning, leading to the loss of rich information contained in the whole network pipeline. Inspired by the assumption that, the small network can not perfectly mimic a large one due to the huge gap of network scale, we propose a knowledge transfer method, involving effective intermediate supervision, under the adversarial training framework to learn the student network. To achieve powerful but highly compact intermediate information representation, the squeezed knowledge is realized by task-driven attention mechanism. Then, the transferred knowledge from teacher network could accommodate the size of student network. As a result, the proposed method integrates merits from both process-oriented and result-oriented learning. Extensive experimental results on three typical benchmark datasets, i.e., CIFAR-10, CIFAR-100, and ImageNet, demonstrate that our method achieves highly superior performances against other state-of-the-art methods.