 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMFC-EQ: Mean-Field Control with Envelope Q-Learning for Moving Decentralized Agents in Formation
Oct 15, 2024We study a decentralized version of Moving Agents in Formation (MAiF), a variant of Multi-Agent Path Finding aiming to plan collision-free paths for multiple agents with the dual objectives of reaching their goals quickly while maintaining a desired formation. The agents must balance these objectives under conditions of partial observation and limited communication. The formation maintenance depends on the joint state of all agents, whose dimensionality increases exponentially with the number of agents, rendering the learning process intractable. Additionally, learning a single policy that can accommodate different linear preferences for these two objectives presents a significant challenge. In this paper, we propose Mean-Field Control with Envelop $Q$-learning (MFC-EQ), a scalable and adaptable learning framework for this bi-objective multi-agent problem. We approximate the dynamics of all agents using mean-field theory while learning a universal preference-agnostic policy through envelop $Q$-learning. Our empirical evaluation of MFC-EQ across numerous instances shows that it outperforms state-of-the-art centralized MAiF baselines. Furthermore, MFC-EQ effectively handles more complex scenarios where the desired formation changes dynamically -- a challenge that existing MAiF planners cannot address.
SACHA: Soft Actor-Critic with Heuristic-Based Attention for Partially Observable Multi-Agent Path Finding
Jul 05, 2023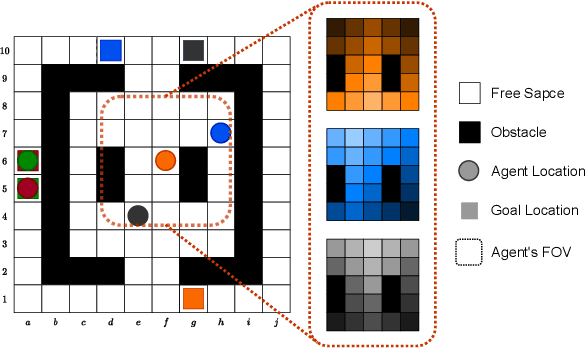
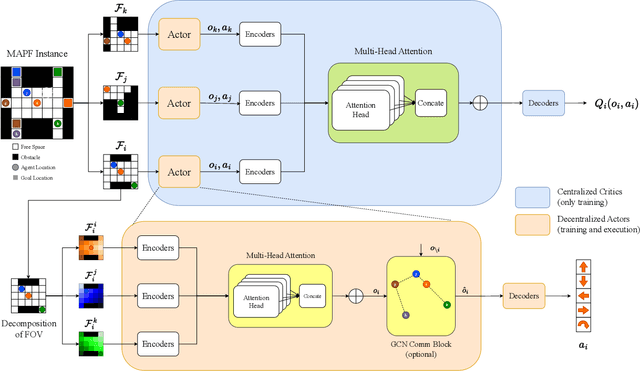
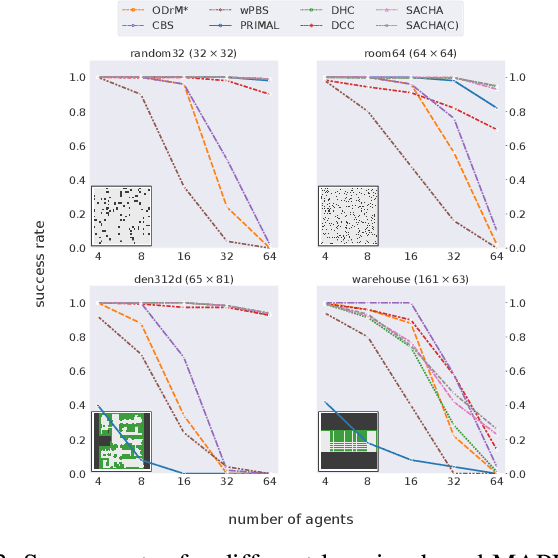

Multi-Agent Path Finding (MAPF) is a crucial component for many large-scale robotic systems, where agents must plan their collision-free paths to their given goal positions. Recently, multi-agent reinforcement learning has been introduced to solve the partially observable variant of MAPF by learning a decentralized single-agent policy in a centralized fashion based on each agent's partial observation. However, existing learning-based methods are ineffective in achieving complex multi-agent cooperation, especially in congested environments, due to the non-stationarity of this setting. To tackle this challenge, we propose a multi-agent actor-critic method called Soft Actor-Critic with Heuristic-Based Attention (SACHA), which employs novel heuristic-based attention mechanisms for both the actors and critics to encourage cooperation among agents. SACHA learns a neural network for each agent to selectively pay attention to the shortest path heuristic guidance from multiple agents within its field of view, thereby allowing for more scalable learning of cooperation. SACHA also extends the existing multi-agent actor-critic framework by introducing a novel critic centered on each agent to approximate $Q$-values. Compared to existing methods that use a fully observable critic, our agent-centered multi-agent actor-critic method results in more impartial credit assignment and better generalizability of the learned policy to MAPF instances with varying numbers of agents and types of environments. We also implement SACHA(C), which embeds a communication module in the agent's policy network to enable information exchange among agents. We evaluate both SACHA and SACHA(C) on a variety of MAPF instances and demonstrate decent improvements over several state-of-the-art learning-based MAPF methods with respect to success rate and solution quality.