 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSIG-VC: A Speaker Information Guided Zero-shot Voice Conversion System for Both Human Beings and Machines
Nov 06, 2021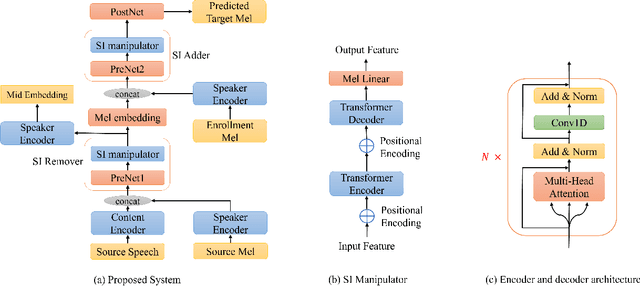

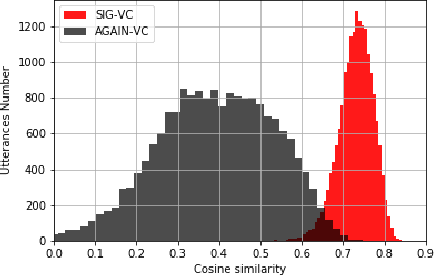

Nowadays, as more and more systems achieve good performance in traditional voice conversion (VC) tasks, people's attention gradually turns to VC tasks under extreme conditions. In this paper, we propose a novel method for zero-shot voice conversion. We aim to obtain intermediate representations for speaker-content disentanglement of speech to better remove speaker information and get pure content information. Accordingly, our proposed framework contains a module that removes the speaker information from the acoustic feature of the source speaker. Moreover, speaker information control is added to our system to maintain the voice cloning performance. The proposed system is evaluated by subjective and objective metrics. Results show that our proposed system significantly reduces the trade-off problem in zero-shot voice conversion, while it also manages to have high spoofing power to the speaker verification system.