 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLanguage Identification of Devanagari Poems
Dec 30, 2020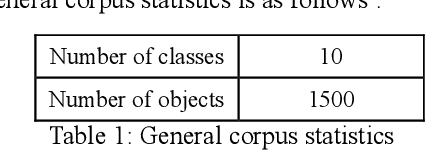
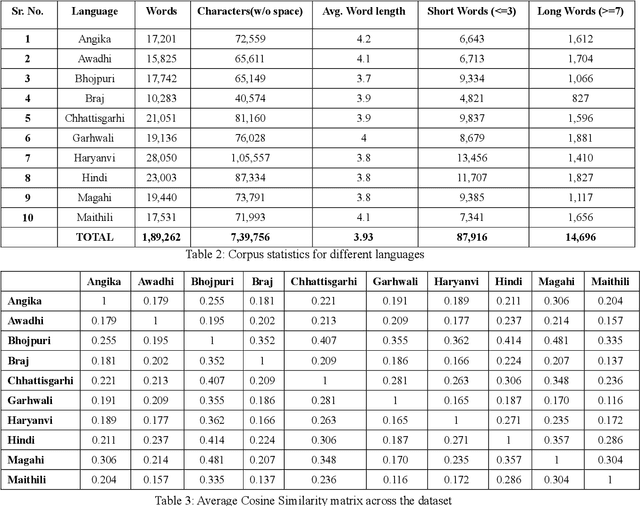
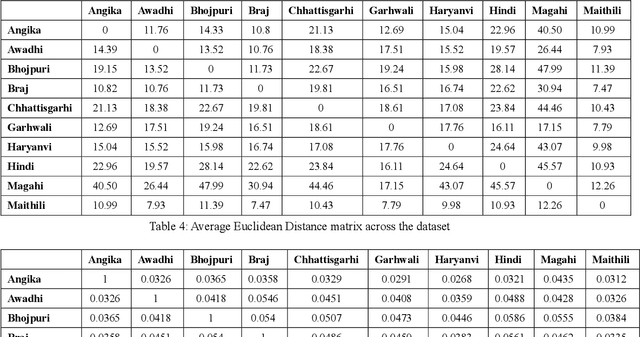
Language Identification is a very important part of several text processing pipelines. Extensive research has been done in this field. This paper proposes a procedure for automatic language identification of poems for poem analysis task, consisting of 10 Devanagari based languages of India i.e. Angika, Awadhi, Braj, Bhojpuri, Chhattisgarhi, Garhwali, Haryanvi, Hindi, Magahi, and Maithili. We collated corpora of poems of varying length and studied the similarity of poems among the 10 languages at the lexical level. Finally, various language identification systems based on supervised machine learning and deep learning techniques are applied and evaluated.
Automatic Parallel Corpus Creation for Hindi-English News Translation Task
Jan 24, 2019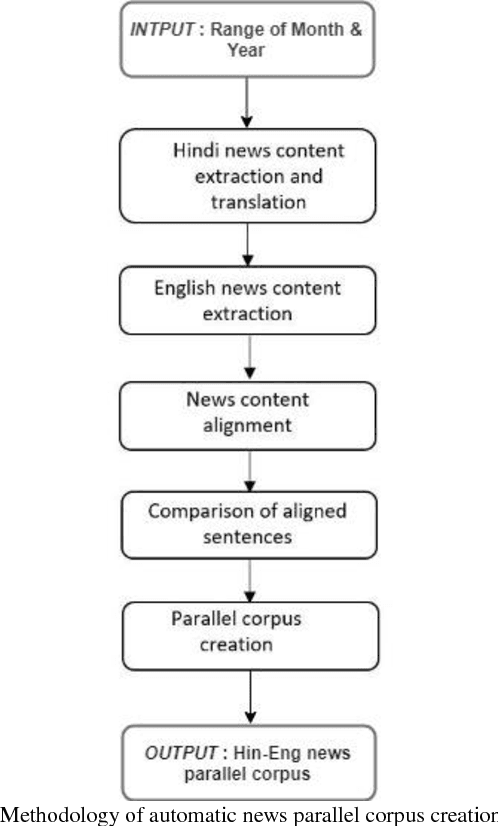



The parallel corpus for multilingual NLP tasks, deep learning applications like Statistical Machine Translation Systems is very important. The parallel corpus of Hindi-English language pair available for news translation task till date is of very limited size as per the requirement of the systems are concerned. In this work we have developed an automatic parallel corpus generation system prototype, which creates Hindi-English parallel corpus for news translation task. Further to verify the quality of generated parallel corpus we have experimented by taking various performance metrics and the results are quite interesting.