 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTask--Specificity Score: Measuring How Much Instructions Really Matter for Supervision
Feb 03, 2026Instruction tuning is now the default way to train and adapt large language models, but many instruction--input--output pairs are only weakly specified: for a given input, the same output can remain plausible under several alternative instructions. This raises a simple question: \emph{does the instruction uniquely determine the target output?} We propose the \textbf{Task--Specificity Score (TSS)} to quantify how much an instruction matters for predicting its output, by contrasting the true instruction against plausible alternatives for the same input. We further introduce \textbf{TSS++}, which uses hard alternatives and a small quality term to mitigate easy-negative effects. Across three instruction datasets (\textsc{Alpaca}, \textsc{Dolly-15k}, \textsc{NI-20}) and three open LLMs (Gemma, Llama, Qwen), we show that selecting task-specific examples improves downstream performance under tight token budgets and complements quality-based filters such as perplexity and IFD.
Model Hubs and Beyond: Analyzing Model Popularity, Performance, and Documentation
Mar 19, 2025


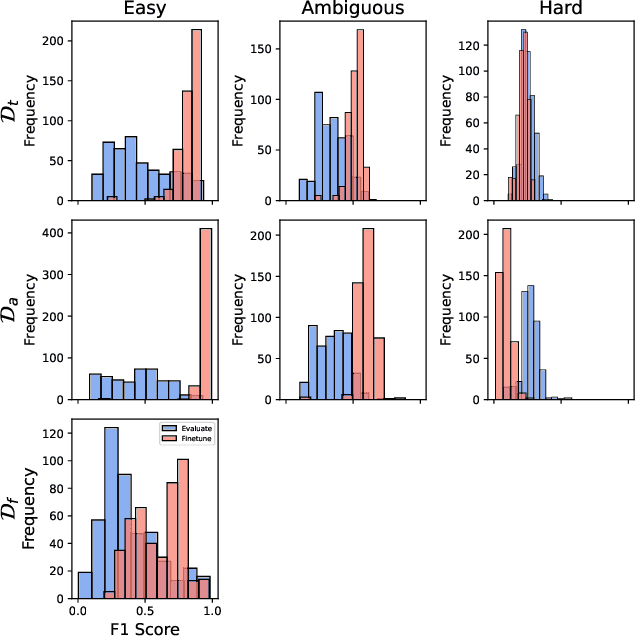
With the massive surge in ML models on platforms like Hugging Face, users often lose track and struggle to choose the best model for their downstream tasks, frequently relying on model popularity indicated by download counts, likes, or recency. We investigate whether this popularity aligns with actual model performance and how the comprehensiveness of model documentation correlates with both popularity and performance. In our study, we evaluated a comprehensive set of 500 Sentiment Analysis models on Hugging Face. This evaluation involved massive annotation efforts, with human annotators completing nearly 80,000 annotations, alongside extensive model training and evaluation. Our findings reveal that model popularity does not necessarily correlate with performance. Additionally, we identify critical inconsistencies in model card reporting: approximately 80\% of the models analyzed lack detailed information about the model, training, and evaluation processes. Furthermore, about 88\% of model authors overstate their models' performance in the model cards. Based on our findings, we provide a checklist of guidelines for users to choose good models for downstream tasks.
Unveiling the Multi-Annotation Process: Examining the Influence of Annotation Quantity and Instance Difficulty on Model Performance
Oct 23, 2023The NLP community has long advocated for the construction of multi-annotator datasets to better capture the nuances of language interpretation, subjectivity, and ambiguity. This paper conducts a retrospective study to show how performance scores can vary when a dataset expands from a single annotation per instance to multiple annotations. We propose a novel multi-annotator simulation process to generate datasets with varying annotation budgets. We show that similar datasets with the same annotation budget can lead to varying performance gains. Our findings challenge the popular belief that models trained on multi-annotation examples always lead to better performance than models trained on single or few-annotation examples.