 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimal Strategies to Perform Multilingual Analysis of Social Content for a Novel Dataset in the Tourism Domain
Nov 20, 2023



The rising influence of social media platforms in various domains, including tourism, has highlighted the growing need for efficient and automated natural language processing (NLP) approaches to take advantage of this valuable resource. However, the transformation of multilingual, unstructured, and informal texts into structured knowledge often poses significant challenges. In this work, we evaluate and compare few-shot, pattern-exploiting and fine-tuning machine learning techniques on large multilingual language models (LLMs) to establish the best strategy to address the lack of annotated data for 3 common NLP tasks in the tourism domain: (1) Sentiment Analysis, (2) Named Entity Recognition, and (3) Fine-grained Thematic Concept Extraction (linked to a semantic resource). Furthermore, we aim to ascertain the quantity of annotated examples required to achieve good performance in those 3 tasks, addressing a common challenge encountered by NLP researchers in the construction of domain-specific datasets. Extensive experimentation on a newly collected and annotated multilingual (French, English, and Spanish) dataset composed of tourism-related tweets shows that current few-shot learning techniques allow us to obtain competitive results for all three tasks with very little annotation data: 5 tweets per label (15 in total) for Sentiment Analysis, 10% of the tweets for location detection (around 160) and 13% (200 approx.) of the tweets annotated with thematic concepts, a highly fine-grained sequence labeling task based on an inventory of 315 classes. This comparative analysis, grounded in a novel dataset, paves the way for applying NLP to new domain-specific applications, reducing the need for manual annotations and circumventing the complexities of rule-based, ad hoc solutions.
A Markovian-based Approach for Daily Living Activities Recognition
Mar 10, 2016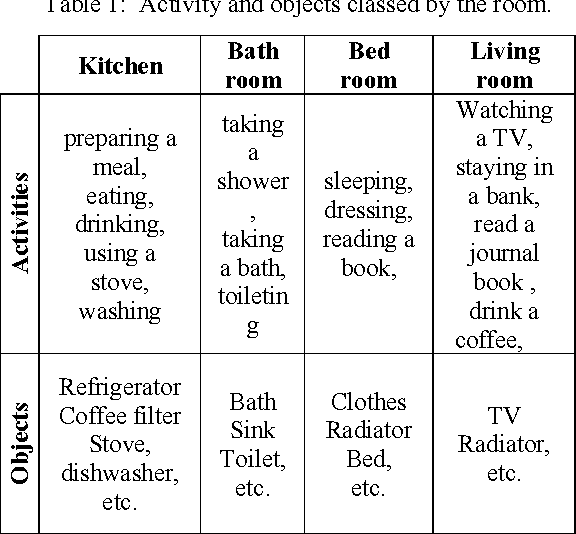
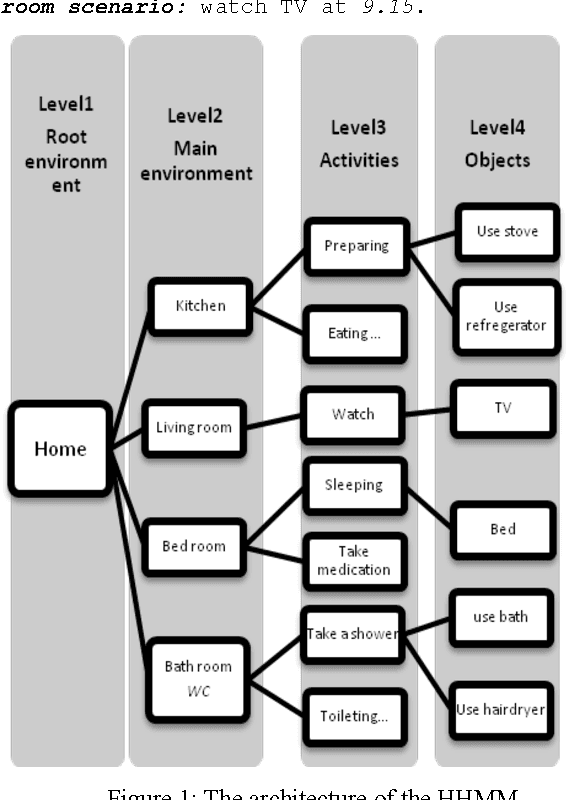
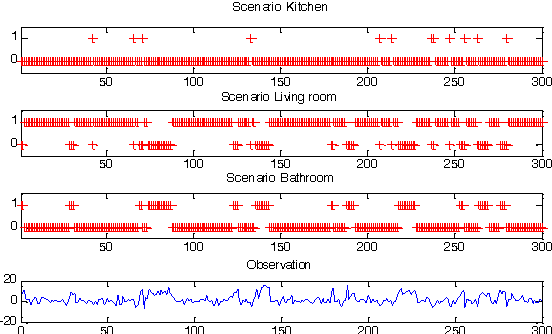
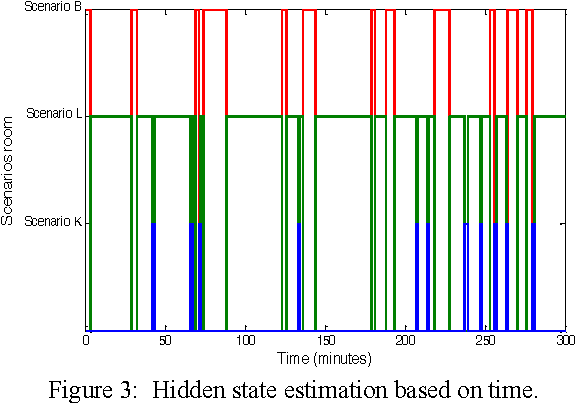
Recognizing the activities of daily living plays an important role in healthcare. It is necessary to use an adapted model to simulate the human behavior in a domestic space to monitor the patient harmonically and to intervene in the necessary time. In this paper, we tackle this problem using the hierarchical hidden Markov model for representing and recognizing complex indoor activities. We propose a new grammar, called "Home By Room Activities Language", to facilitate the complexity of human scenarios and consider the abnormal activities.