 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComputing patient similarity based on unstructured clinical notes
Jan 12, 2026Clinical notes hold rich yet unstructured details about diagnoses, treatments, and outcomes that are vital to precision medicine but hard to exploit at scale. We introduce a method that represents each patient as a matrix built from aggregated embeddings of all their notes, enabling robust patient similarity computation based on their latent low-rank representations. Using clinical notes of 4,267 Czech breast-cancer patients and expert similarity labels from Masaryk Memorial Cancer Institute, we evaluate several matrix-based similarity measures and analyze their strengths and limitations across different similarity facets, such as clinical history, treatment, and adverse events. The results demonstrate the usefulness of the presented method for downstream tasks, such as personalized therapy recommendations or toxicity warnings.
* This is a preprint and has not undergone peer review. Final version was presented at the Text, Speech, and Dialogue 2025 conference. The Version of Record is available at https://doi.org/10.1007/978-3-032-02551-7_13
Unsupervised extraction, labelling and clustering of segments from clinical notes
Nov 21, 2022
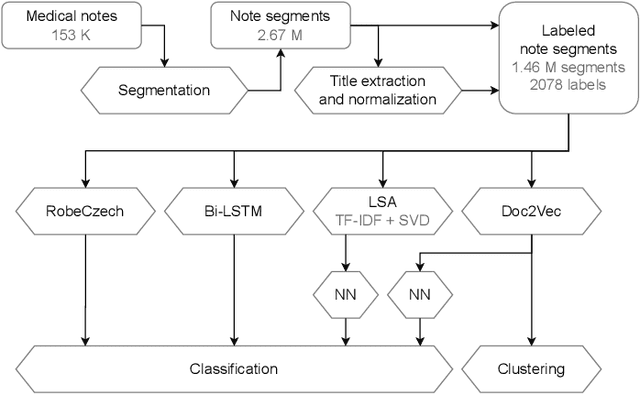


This work is motivated by the scarcity of tools for accurate, unsupervised information extraction from unstructured clinical notes in computationally underrepresented languages, such as Czech. We introduce a stepping stone to a broad array of downstream tasks such as summarisation or integration of individual patient records, extraction of structured information for national cancer registry reporting or building of semi-structured semantic patient representations for computing patient embeddings. More specifically, we present a method for unsupervised extraction of semantically-labelled textual segments from clinical notes and test it out on a dataset of Czech breast cancer patients, provided by Masaryk Memorial Cancer Institute (the largest Czech hospital specialising in oncology). Our goal was to extract, classify (i.e. label) and cluster segments of the free-text notes that correspond to specific clinical features (e.g., family background, comorbidities or toxicities). The presented results demonstrate the practical relevance of the proposed approach for building more sophisticated extraction and analytical pipelines deployed on Czech clinical notes.