Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Finnish News Corpus for Named Entity Recognition
Aug 12, 2019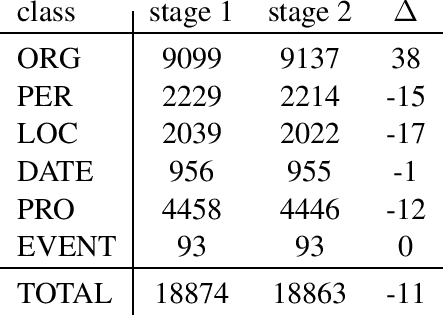
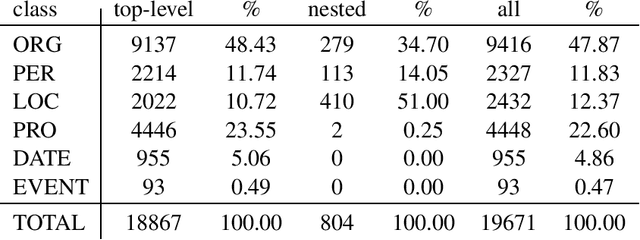
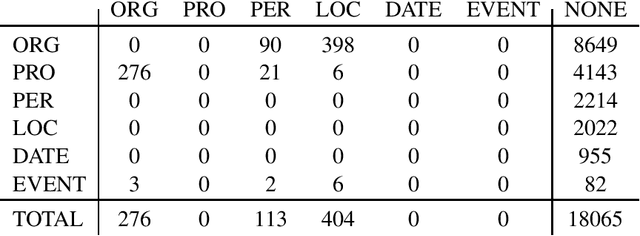
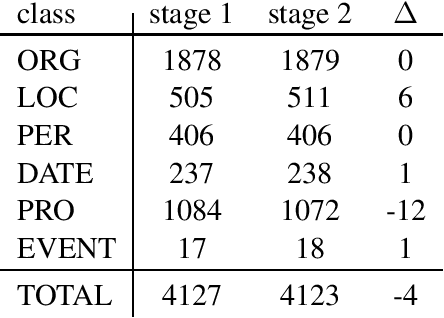
We present a corpus of Finnish news articles with a manually prepared named entity annotation. The corpus consists of 953 articles (193,742 word tokens) with six named entity classes (organization, location, person, product, event, and date). The articles are extracted from the archives of Digitoday, a Finnish online technology news source. The corpus is available for research purposes. We present baseline experiments on the corpus using a rule-based and two deep learning systems on two, in-domain and out-of-domain, test sets.
Via