 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn investigation on selecting audio pre-trained models for audio captioning
Aug 12, 2022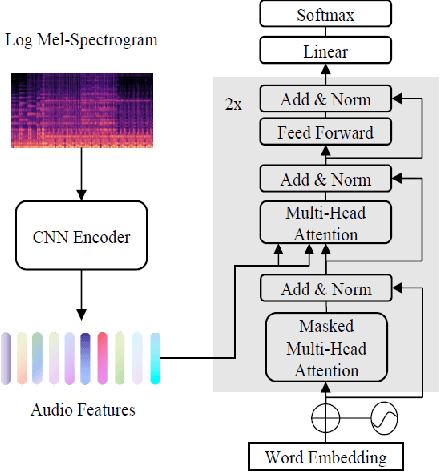
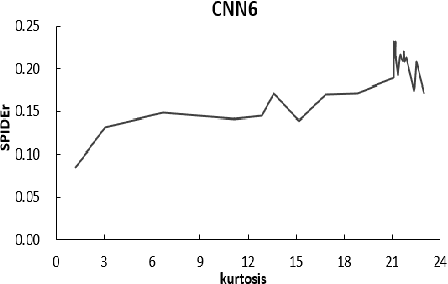
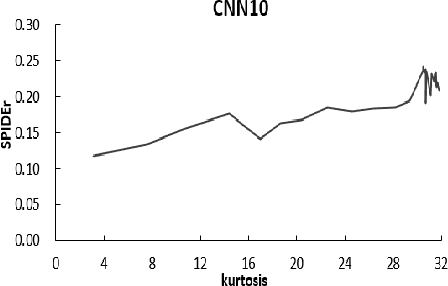

Audio captioning is a task that generates description of audio based on content. Pre-trained models are widely used in audio captioning due to high complexity. Unless a comprehensive system is re-trained, it is hard to determine how well pre-trained models contribute to audio captioning system. To prevent the time consuming and energy consuming process of retraining, it is necessary to propose a preditor of performance for the pre-trained model in audio captioning. In this paper, a series of pre-trained models are investigated for the correlation between extracted audio features and the performance of audio captioning. A couple of predictor is proposed based on the experiment results.The result demonstrates that the kurtosis and skewness of audio features extracted may act as an indicator of the performance of audio captioning systems for pre-trained audio due to the high correlation between kurtosis and skewness of audio features and the performance of audio captioning systems.