 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Performance in Classification Tasks with LCEN and the Weighted Focal Differentiable MCC Loss
Apr 23, 2026The LASSO-Clip-EN (LCEN) algorithm was previously introduced for nonlinear, interpretable feature selection and machine learning. However, its design and use was limited to regression tasks. In this work, we create a modified version of the LCEN algorithm that is suitable for classification tasks and maintains its desirable properties, such as interpretability. This modified LCEN algorithm is evaluated on four widely used binary and multiclass classification datasets. In these experiments, LCEN is compared against 10 other model types and consistently reaches high test-set macro F$_1$ score and Matthews correlation coefficient (MCC) metrics, higher than that of the majority of investigated models. LCEN models for classification remain sparse, eliminating an average of 56% of all input features in the experiments performed. Furthermore, LCEN-selected features are used to retrain all models using the same data, leading to statistically significant performance improvements in three of the experiments and insignificant differences in the fourth when compared to using all features or other feature selection methods. Simultaneously, the weighted focal differentiable MCC (diffMCC) loss function is evaluated on the same datasets. Models trained with the diffMCC loss function are always the best-performing methods in these experiments, and reach test-set macro F$_1$ scores that are, on average, 4.9% higher and MCCs that are 8.5% higher than those obtained by models trained with the weighted cross-entropy loss. These results highlight the performance of LCEN as a feature selection and machine learning algorithm also for classification tasks, and how the diffMCC loss function can train very accurate models, surpassing the weighted cross-entropy loss in the tasks investigated.
LCEN: A Novel Feature Selection Algorithm for Nonlinear, Interpretable Machine Learning Models
Feb 27, 2024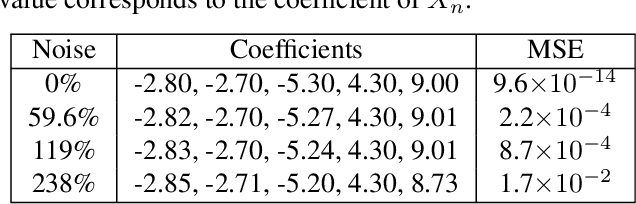
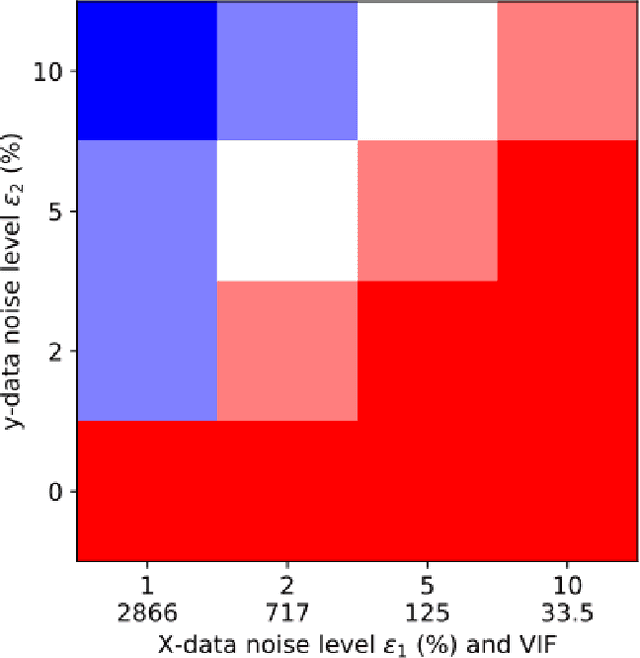
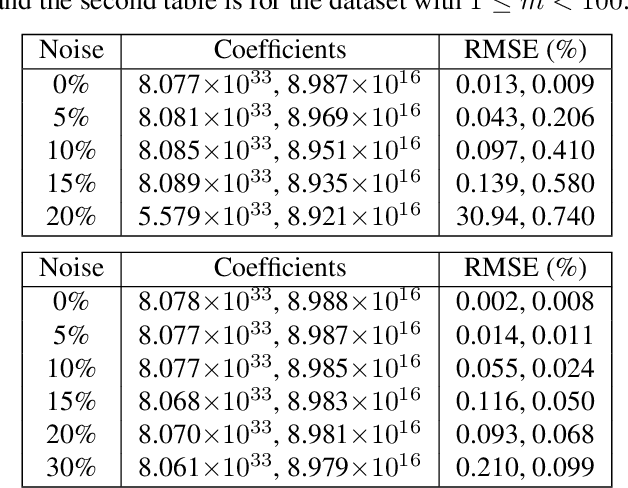
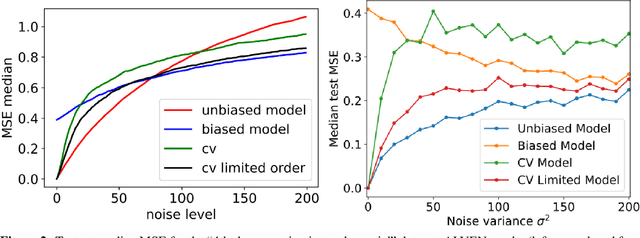
Interpretable architectures can have advantages over black-box architectures, and interpretability is essential for the application of machine learning in critical settings, such as aviation or medicine. However, the simplest, most commonly used interpretable architectures (such as LASSO or EN) are limited to linear predictions and have poor feature selection capabilities. In this work, we introduce the LASSO-Clip-EN (LCEN) algorithm for the creation of nonlinear, interpretable machine learning models. LCEN is tested on a wide variety of artificial and empirical datasets, creating more accurate, sparser models than other commonly used architectures. These experiments reveal that LCEN is robust against many issues typically present in datasets and modeling, including noise, multicollinearity, data scarcity, and hyperparameter variance. LCEN is also able to rediscover multiple physical laws from empirical data and, for processes with no known physical laws, LCEN achieves better results than many other dense and sparse methods -- including using 10.8 times fewer features than dense methods and 8.1 times fewer features than EN on one dataset, and is comparable to an ANN on another dataset.
Predicting O-GlcNAcylation Sites in Mammalian Proteins with Transformers and RNNs Trained with a New Loss Function
Feb 27, 2024Glycosylation, a protein modification, has multiple essential functional and structural roles. O-GlcNAcylation, a subtype of glycosylation, has the potential to be an important target for therapeutics, but methods to reliably predict O-GlcNAcylation sites had not been available until 2023; a 2021 review correctly noted that published models were insufficient and failed to generalize. Moreover, many are no longer usable. In 2023, a considerably better RNN model with an F$_1$ score of 36.17% and an MCC of 34.57% on a large dataset was published. This article first sought to improve these metrics using transformer encoders. While transformers displayed high performance on this dataset, their performance was inferior to that of the previously published RNN. We then created a new loss function, which we call the weighted focal differentiable MCC, to improve the performance of classification models. RNN models trained with this new function display superior performance to models trained using the weighted cross-entropy loss; this new function can also be used to fine-tune trained models. A two-cell RNN trained with this loss achieves state-of-the-art performance in O-GlcNAcylation site prediction with an F$_1$ score of 38.82% and an MCC of 38.21% on that large dataset.