 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCombining Deep Learning Classifiers for 3D Action Recognition
Apr 21, 2020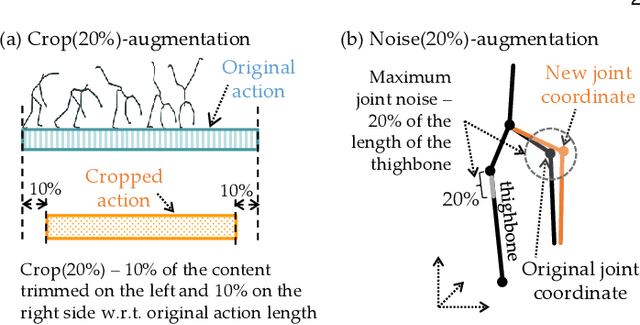
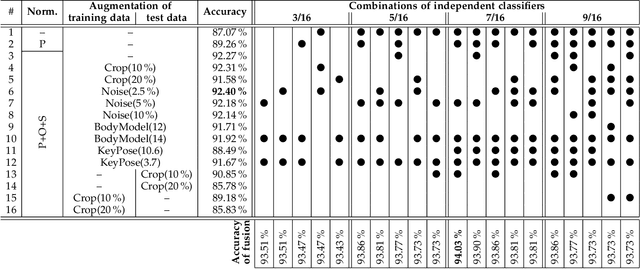
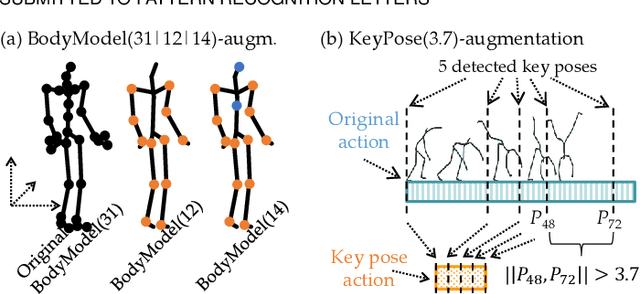
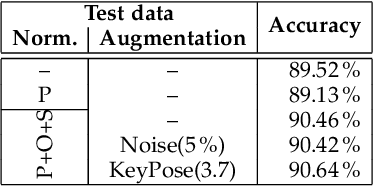
The popular task of 3D human action recognition is almost exclusively solved by training deep-learning classifiers. To achieve a high recognition accuracy, the input 3D actions are often pre-processed by various normalization or augmentation techniques. However, it is not computationally feasible to train a classifier for each possible variant of training data in order to select the best-performing subset of pre-processing techniques for a given dataset. In this paper, we propose to train an independent classifier for each available pre-processing technique and fuse the classification results based on a strict majority vote rule. Together with a proposed evaluation procedure, we can very efficiently determine the best combination of normalization and augmentation techniques for a specific dataset. For the best-performing combination, we can retrospectively apply the normalized/augmented variants of input data to train only a single classifier. This also allows us to decide whether it is better to train a single model, or rather a set of independent classifiers.
DISA at ImageCLEF 2014 Revised: Search-based Image Annotation with DeCAF Features
Sep 16, 2014
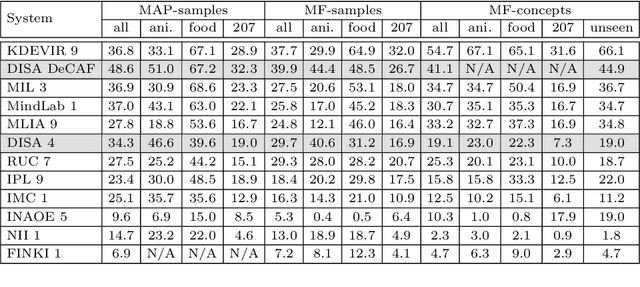
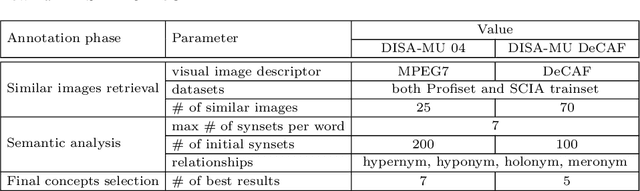
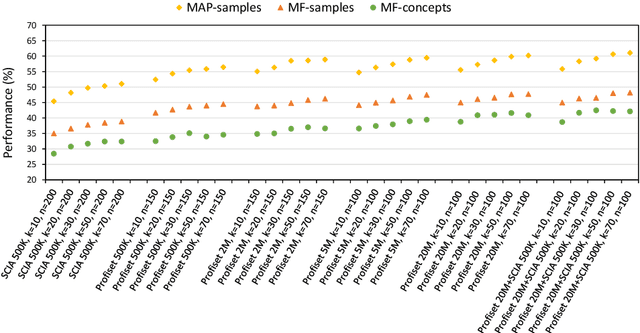
This paper constitutes an extension to the report on DISA-MU team participation in the ImageCLEF 2014 Scalable Concept Image Annotation Task as published in [3]. Specifically, we introduce a new similarity search component that was implemented into the system, report on the results achieved by utilizing this component, and analyze the influence of different similarity search parameters on the annotation quality.