 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDesigning Interfaces for Multimodal Vector Search Applications
Sep 18, 2024
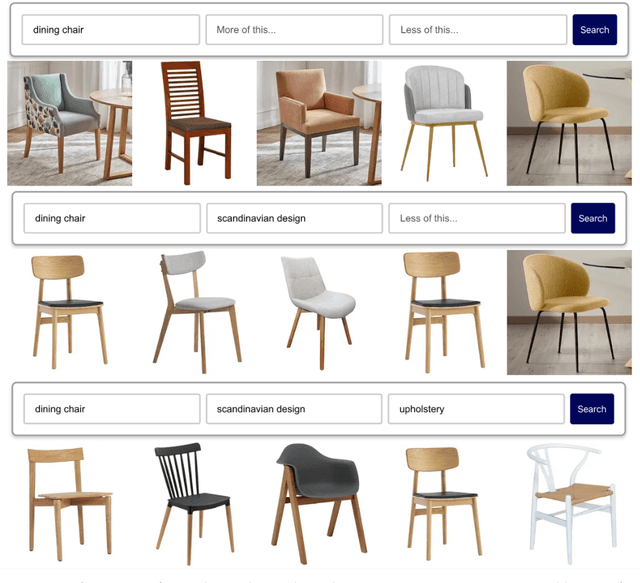
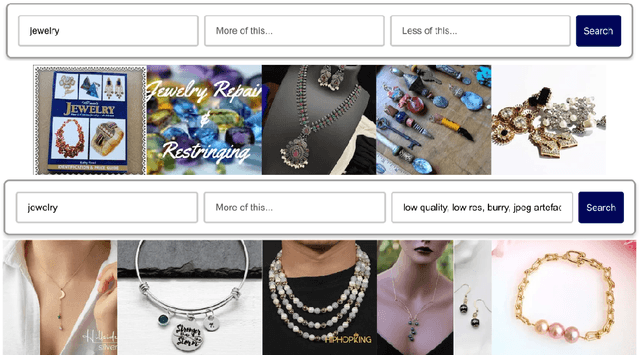

Multimodal vector search offers a new paradigm for information retrieval by exposing numerous pieces of functionality which are not possible in traditional lexical search engines. While multimodal vector search can be treated as a drop in replacement for these traditional systems, the experience can be significantly enhanced by leveraging the unique capabilities of multimodal search. Central to any information retrieval system is a user who expresses an information need, traditional user interfaces with a single search bar allow users to interact with lexical search systems effectively however are not necessarily optimal for multimodal vector search. In this paper we explore novel capabilities of multimodal vector search applications utilising CLIP models and present implementations and design patterns which better allow users to express their information needs and effectively interact with these systems in an information retrieval context.
The Impacts of Data, Ordering, and Intrinsic Dimensionality on Recall in Hierarchical Navigable Small Worlds
May 28, 2024Vector search systems, pivotal in AI applications, often rely on the Hierarchical Navigable Small Worlds (HNSW) algorithm. However, the behaviour of HNSW under real-world scenarios using vectors generated with deep learning models remains under-explored. Existing Approximate Nearest Neighbours (ANN) benchmarks and research typically has an over-reliance on simplistic datasets like MNIST or SIFT1M and fail to reflect the complexity of current use-cases. Our investigation focuses on HNSW's efficacy across a spectrum of datasets, including synthetic vectors tailored to mimic specific intrinsic dimensionalities, widely-used retrieval benchmarks with popular embedding models, and proprietary e-commerce image data with CLIP models. We survey the most popular HNSW vector databases and collate their default parameters to provide a realistic fixed parameterisation for the duration of the paper. We discover that the recall of approximate HNSW search, in comparison to exact K Nearest Neighbours (KNN) search, is linked to the vector space's intrinsic dimensionality and significantly influenced by the data insertion sequence. Our methodology highlights how insertion order, informed by measurable properties such as the pointwise Local Intrinsic Dimensionality (LID) or known categories, can shift recall by up to 12 percentage points. We also observe that running popular benchmark datasets with HNSW instead of KNN can shift rankings by up to three positions for some models. This work underscores the need for more nuanced benchmarks and design considerations in developing robust vector search systems using approximate vector search algorithms. This study presents a number of scenarios with varying real world applicability which aim to better increase understanding and future development of ANN algorithms and embedding