 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAsymptotic Behavior of Multi--Task Learning: Implicit Regularization and Double Descent Effects
Mar 05, 2026Multi--task learning seeks to improve the generalization error by leveraging the common information shared by multiple related tasks. One challenge in multi--task learning is identifying formulations capable of uncovering the common information shared between different but related tasks. This paper provides a precise asymptotic analysis of a popular multi--task formulation associated with misspecified perceptron learning models. The main contribution of this paper is to precisely determine the reasons behind the benefits gained from combining multiple related tasks. Specifically, we show that combining multiple tasks is asymptotically equivalent to a traditional formulation with additional regularization terms that help improve the generalization performance. Another contribution is to empirically study the impact of combining tasks on the generalization error. In particular, we empirically show that the combination of multiple tasks postpones the double descent phenomenon and can mitigate it asymptotically.
On the Inherent Regularization Effects of Noise Injection During Training
Feb 15, 2021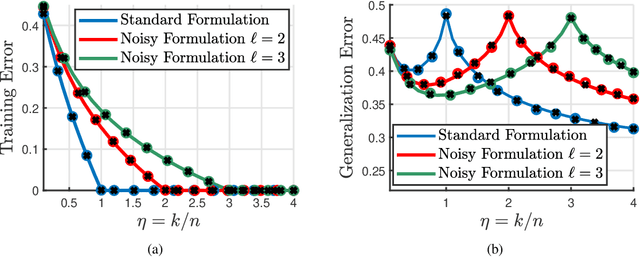
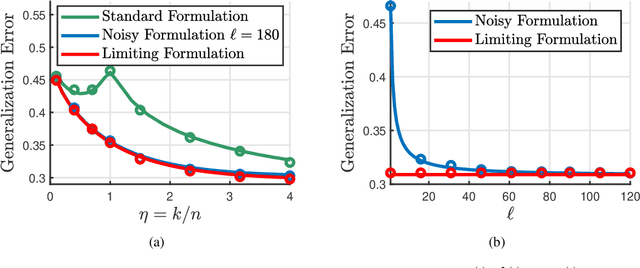
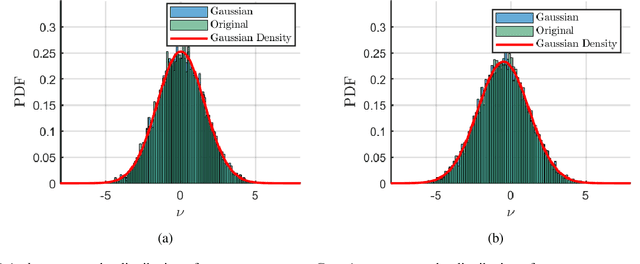
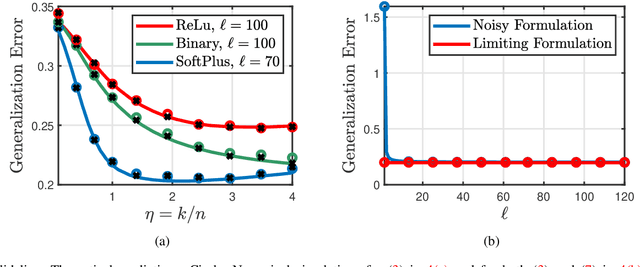
Randomly perturbing networks during the training process is a commonly used approach to improving generalization performance. In this paper, we present a theoretical study of one particular way of random perturbation, which corresponds to injecting artificial noise to the training data. We provide a precise asymptotic characterization of the training and generalization errors of such randomly perturbed learning problems on a random feature model. Our analysis shows that Gaussian noise injection in the training process is equivalent to introducing a weighted ridge regularization, when the number of noise injections tends to infinity. The explicit form of the regularization is also given. Numerical results corroborate our asymptotic predictions, showing that they are accurate even in moderate problem dimensions. Our theoretical predictions are based on a new correlated Gaussian equivalence conjecture that generalizes recent results in the study of random feature models.
Phase Transitions in Transfer Learning for High-Dimensional Perceptrons
Jan 06, 2021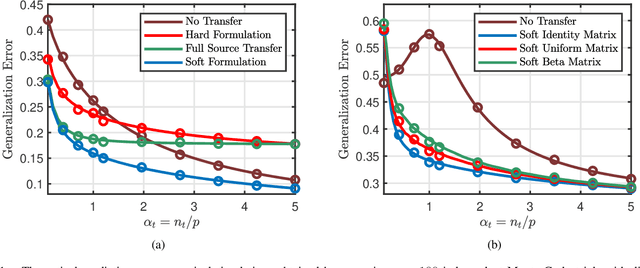


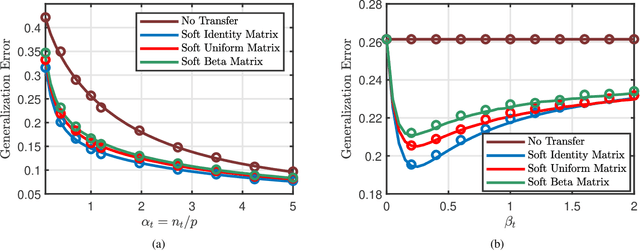
Transfer learning seeks to improve the generalization performance of a target task by exploiting the knowledge learned from a related source task. Central questions include deciding what information one should transfer and when transfer can be beneficial. The latter question is related to the so-called negative transfer phenomenon, where the transferred source information actually reduces the generalization performance of the target task. This happens when the two tasks are sufficiently dissimilar. In this paper, we present a theoretical analysis of transfer learning by studying a pair of related perceptron learning tasks. Despite the simplicity of our model, it reproduces several key phenomena observed in practice. Specifically, our asymptotic analysis reveals a phase transition from negative transfer to positive transfer as the similarity of the two tasks moves past a well-defined threshold.