 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIt's All About The Scale -- Efficient Text Detection Using Adaptive Scaling
Jul 28, 2019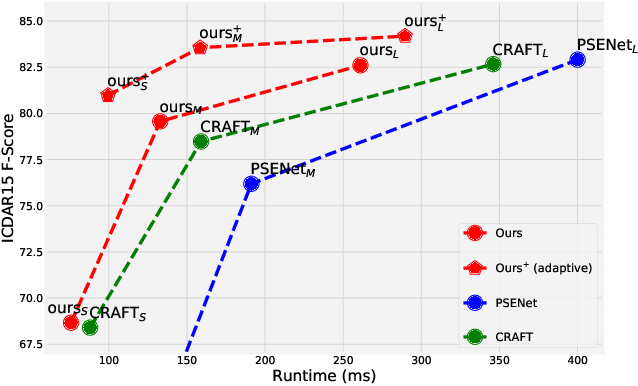
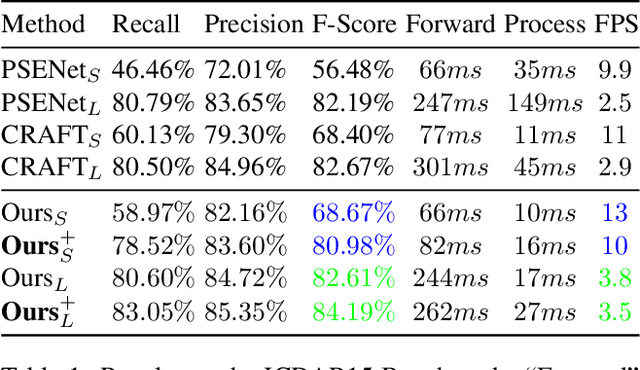

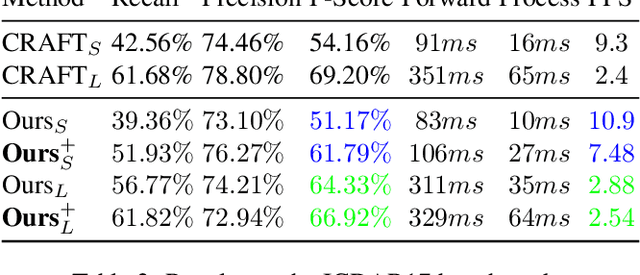
"Text can appear anywhere". This property requires us to carefully process all the pixels in an image in order to accurately localize all text instances. In particular, for the more difficult task of localizing small text regions, many methods use an enlarged image or even several rescaled ones as their input. This significantly increases the processing time of the entire image and needlessly enlarges background regions. If we were to have a prior telling us the coarse location of text instances in the image and their approximate scale, we could have adaptively chosen which regions to process and how to rescale them, thus significantly reducing the processing time. To estimate this prior we propose a segmentation-based network with an additional "scale predictor", an output channel that predicts the scale of each text segment. The network is applied on a scaled down image to efficiently approximate the desired prior, without processing all the pixels of the original image. The approximated prior is then used to create a compact image containing only text regions, resized to a canonical scale, which is fed again to the segmentation network for fine-grained detection. We show that our approach offers a powerful alternative to fixed scaling schemes, achieving an equivalent accuracy to larger input scales while processing far fewer pixels. Qualitative and quantitative results are presented on the ICDAR15 and ICDAR17 MLT benchmarks to validate our approach.