 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOmniLoc: A Geometry-Aware Foundation Model for Anchor-Free UE Localization Across Diverse Indoor Environments
Jun 09, 2026Indoor localization from wireless measurements remains challenging in large-scale deployments due to substantial variation in building geometry, the set of detectable access points (APs), and the heterogeneity of received signals. Existing learning-based methods often perform well only in limited settings and degrade under environmental shifts, making robust anchor-free localization across diverse indoor environments notoriously difficult. In this paper, we present OmniLoc, an environment-interactive foundation model for anchor-free user equipment localization across diverse indoor environments. To the best of our knowledge, OmniLoc is the first foundation-model-based approach built directly on wireless measurements for this task. OmniLoc is built on three key designs. First, a unified input tokenization module converts heterogeneous wireless measurements into a common representation that is more amenable to learning. Second, a geometry-aware Transformer performs AP-aware feature extraction by emphasizing dominant APs while aggregating complementary evidence from supporting APs. Third, a geometry-aware location estimation module conditions regression on geometric embeddings to produce geometrically consistent location predictions. We evaluate OmniLoc on both a large-scale in-house dataset and a public benchmark dataset. Results show that OmniLoc significantly outperforms existing methods, consistently improves existing backbones when its design components are integrated, and demonstrates strong generalization in cross-environment evaluations.
WiLoc: Massive Measured Dataset of Wi-Fi Channel State Information with Application to Machine-Learning Based Localization
Feb 09, 2026Localization is a key component of the wireless ecosystem. Machine learning (ML)-based localization using channel state information (CSI) is one of the most popular methods for achieving high-accuracy localization with low cost. However, to be accurate and robust, ML-based algorithms need to be trained and tested with large amounts of data, covering not only many user equipment (UE)/target locations, but also many different access points (APs) locations to which the UEs connect, in a variety of different environment types. This paper presents a massive-sized CSI dataset, WiLoc (Wi-Fi Localization), and makes it publicly available. WiLoc is obtained by a series of precision measurement campaigns that span three months, and it is massive in all the above-mentioned three dimensions: > 12 million UE locations, > 3,000 APs, covering 16 buildings for indoor localization, and > 30 streets for outdoor use. The paper describes the dataset structure, measurement environments, measurement protocols, and the dataset validations. Comprehensive case studies validate the advantages of large datasets in ML-driven localization strategies for both "standard" and transfer learning. We envision this dataset, which is by far the largest of its kind, to become a standard resource for researchers in the field of ML-based localization.
Wireless Channel Aware Data Augmentation Methods for Deep Leaning-Based Indoor Localization
Aug 12, 2024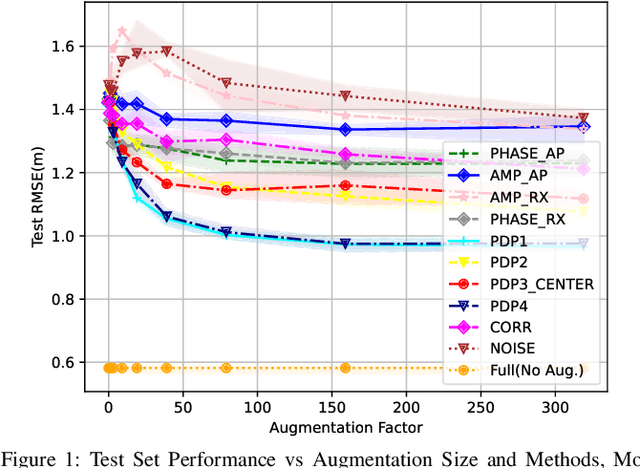
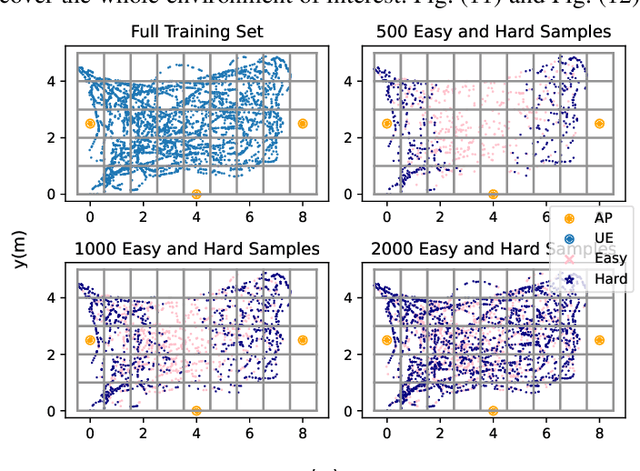
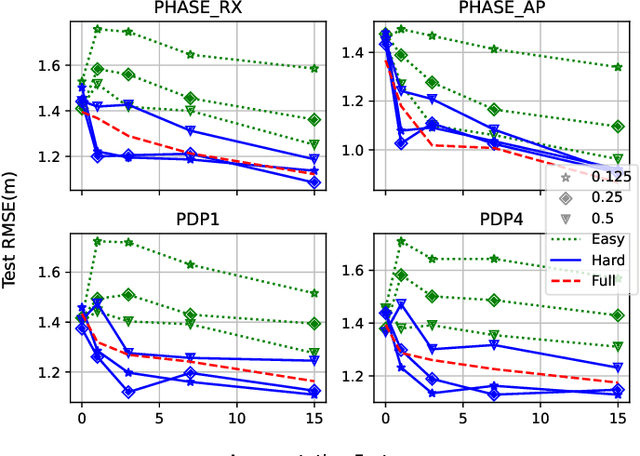
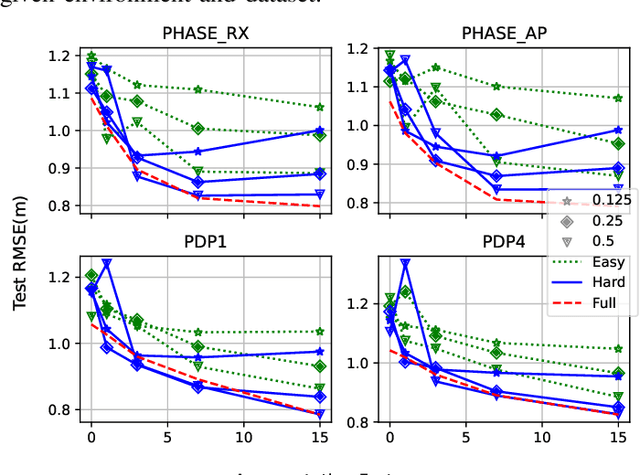
Indoor localization is a challenging problem that - unlike outdoor localization - lacks a universal and robust solution. Machine Learning (ML), particularly Deep Learning (DL), methods have been investigated as a promising approach. Although such methods bring remarkable localization accuracy, they heavily depend on the training data collected from the environment. The data collection is usually a laborious and time-consuming task, but Data Augmentation (DA) can be used to alleviate this issue. In this paper, different from previously used DA, we propose methods that utilize the domain knowledge about wireless propagation channels and devices. The methods exploit the typical hardware component drift in the transceivers and/or the statistical behavior of the channel, in combination with the measured Power Delay Profile (PDP). We comprehensively evaluate the proposed methods to demonstrate their effectiveness. This investigation mainly focuses on the impact of factors such as the number of measurements, augmentation proportion, and the environment of interest impact the effectiveness of the different DA methods. We show that in the low-data regime (few actual measurements available), localization accuracy increases up to 50%, matching non-augmented results in the high-data regime. In addition, the proposed methods may outperform the measurement-only high-data performance by up to 33% using only 1/4 of the amount of measured data. We also exhibit the effect of different training data distribution and quality on the effectiveness of DA. Finally, we demonstrate the power of the proposed methods when employed along with Transfer Learning (TL) to address the data scarcity in target and/or source environments.
Simple and Effective Augmentation Methods for CSI Based Indoor Localization
Nov 19, 2022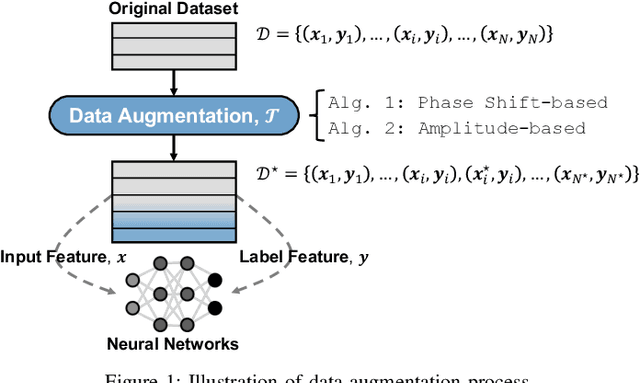
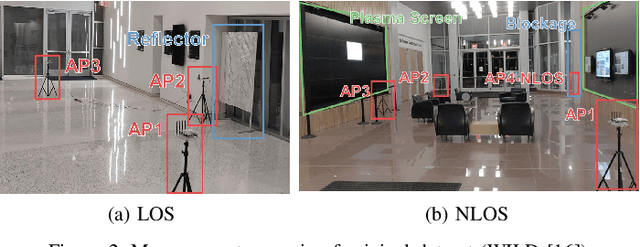
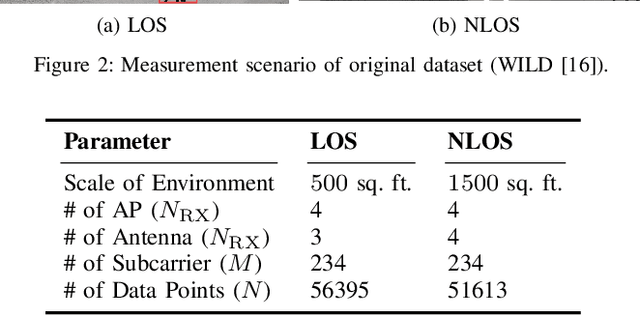
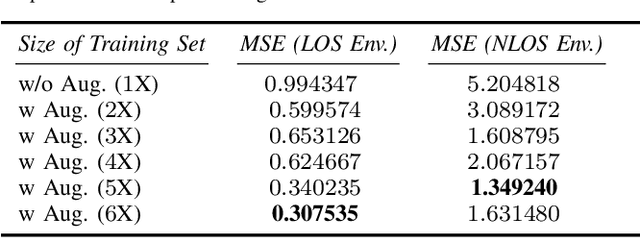
Indoor localization is a challenging task. There is no robust and almost-universal approach, in contrast to outdoor environments where GPS is dominant. Recently, machine learning (ML) has emerged as the most promising approach for achieving accurate indoor localization, yet its main challenge is the requirement for large datasets to train the neural networks. The data collection procedure is costly and laborious as the procedure requires extensive measurements and labeling processes for different indoor environments. The situation can be improved by Data Augmentation (DA), which is a general framework to enlarge the datasets for ML, making ML systems more robust and increases their generalization capabilities. In this paper, we propose two simple yet surprisingly effective DA algorithms for channel state information (CSI) based indoor localization motivated by physical considerations. We show that the required number of measurements for a given accuracy requirement may be decreased by an order of magnitude. Specifically, we demonstrate the algorithms' effectiveness by experiments conducted with a measured indoor WiFi measurement dataset: as little as 10% of the original dataset size is enough to get the same performance of the original dataset. We also showed that, if we further augment the dataset with proposed techniques we get better test accuracy more than three-fold.
PMNet: Robust Pathloss Map Prediction via Supervised Learning
Nov 18, 2022



Pathloss prediction is an essential component of wireless network planning. While ray-tracing based methods have been successfully used for many years, they require significant computational effort that may become prohibitive with the increased network densification and/or use of higher frequencies in 5G/B5G (beyond 5 G) systems. In this paper, we propose and evaluate a data-driven and model-free pathloss prediction method, dubbed PMNet. This method uses a supervised learning approach: training a neural network (NN) with a limited amount of ray tracing (or channel measurement) data and map data and then predicting the pathloss over location with no ray tracing data with a high level of accuracy. Our proposed pathloss map prediction-oriented NN architecture, which is empowered by state-of-the-art computer vision techniques, outperforms other architectures that have been previously proposed (e.g., UNet, RadioUNet) in terms of accuracy while showing generalization capability. Moreover, PMNet trained on a 4-fold smaller dataset surpasses the other baselines (trained on a 4-fold larger dataset), corroborating the potential of PMNet.