 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOrganic Data-Driven Approach for Turkish Grammatical Error Correction and LLMs
May 24, 2024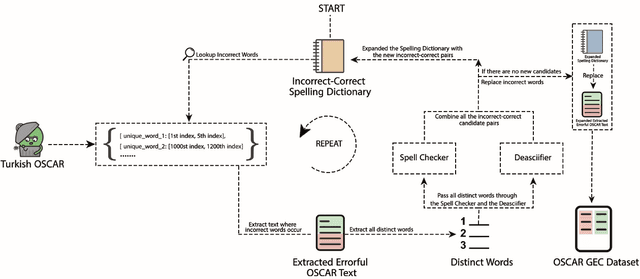
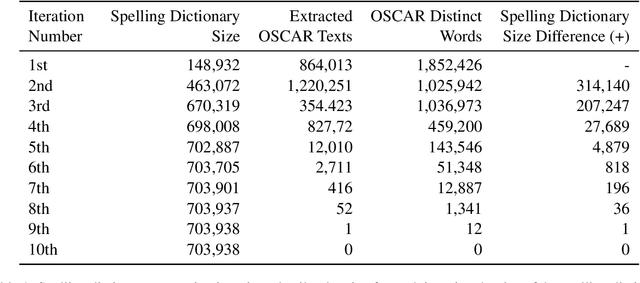
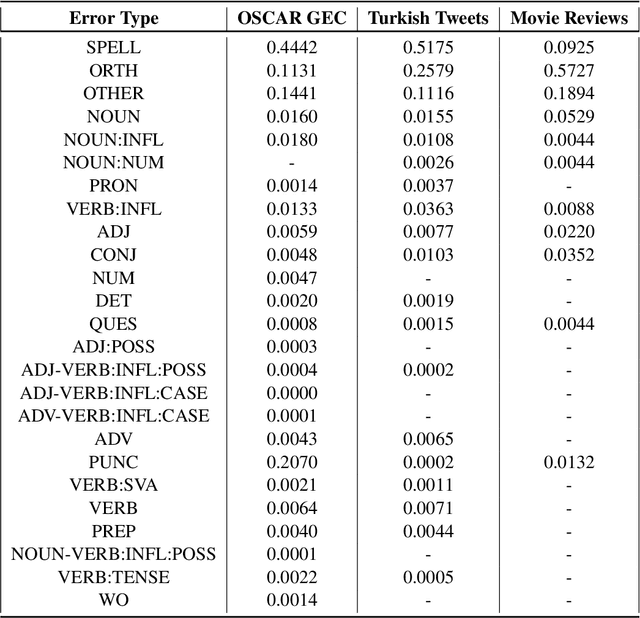

Grammatical Error Correction has seen significant progress with the recent advancements in deep learning. As those methods require huge amounts of data, synthetic datasets are being built to fill this gap. Unfortunately, synthetic datasets are not organic enough in some cases and even require clean data to start with. Furthermore, most of the work that has been done is focused mostly on English. In this work, we introduce a new organic data-driven approach, clean insertions, to build parallel Turkish Grammatical Error Correction datasets from any organic data, and to clean the data used for training Large Language Models. We achieve state-of-the-art results on two Turkish Grammatical Error Correction test sets out of the three publicly available ones. We also show the effectiveness of our method on the training losses of training language models.