 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Neural Compression with Inference-time Decoding
Jun 10, 2024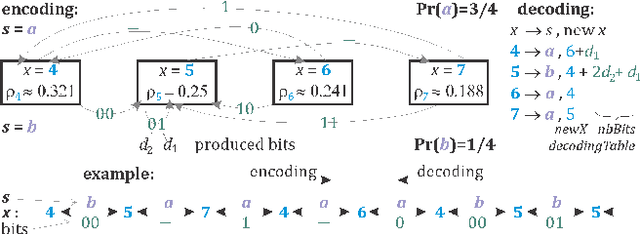
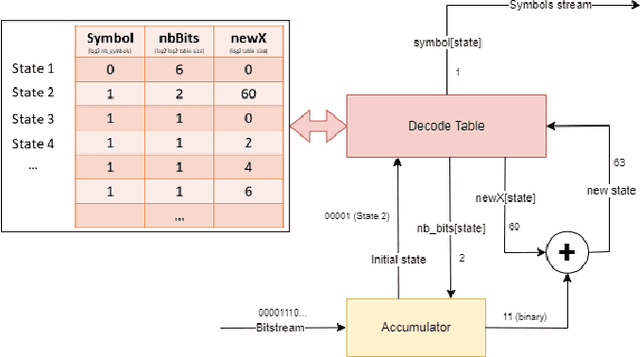
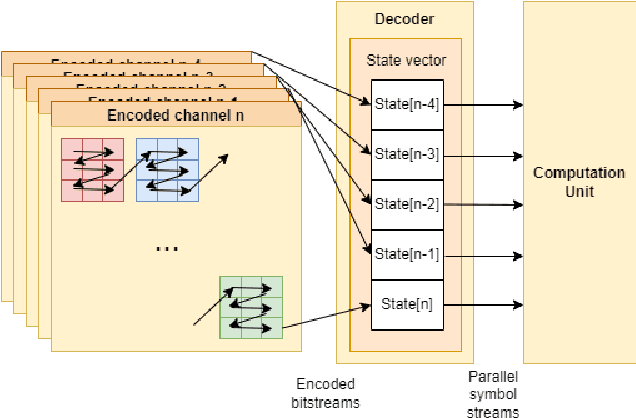
This paper explores the combination of neural network quantization and entropy coding for memory footprint minimization. Edge deployment of quantized models is hampered by the harsh Pareto frontier of the accuracy-to-bitwidth tradeoff, causing dramatic accuracy loss below a certain bitwidth. This accuracy loss can be alleviated thanks to mixed precision quantization, allowing for more flexible bitwidth allocation. However, standard mixed precision benefits remain limited due to the 1-bit frontier, that forces each parameter to be encoded on at least 1 bit of data. This paper introduces an approach that combines mixed precision, zero-point quantization and entropy coding to push the compression boundary of Resnets beyond the 1-bit frontier with an accuracy drop below 1% on the ImageNet benchmark. From an implementation standpoint, a compact decoder architecture features reduced latency, thus allowing for inference-compatible decoding.
OvA-INN: Continual Learning with Invertible Neural Networks
Jun 24, 2020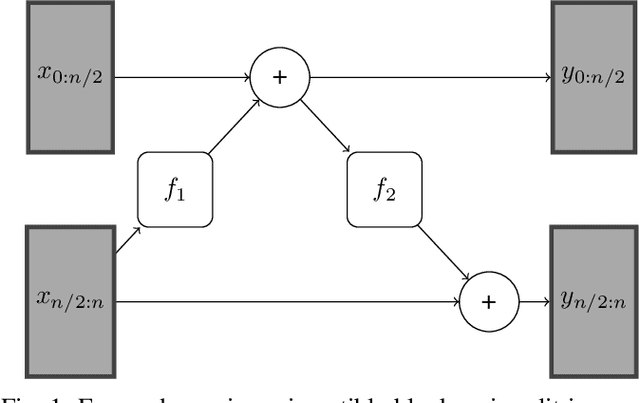
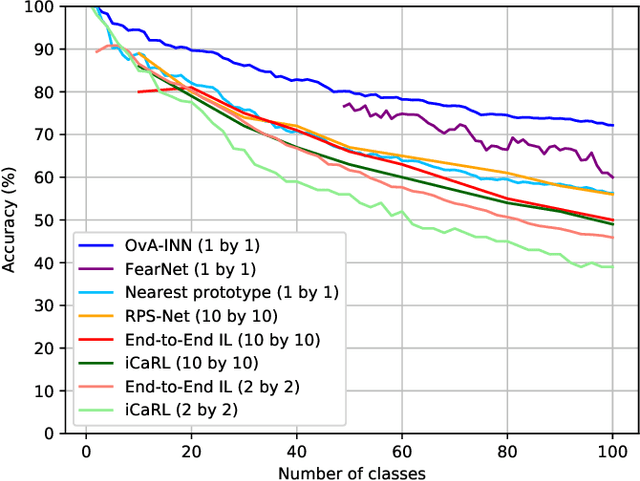
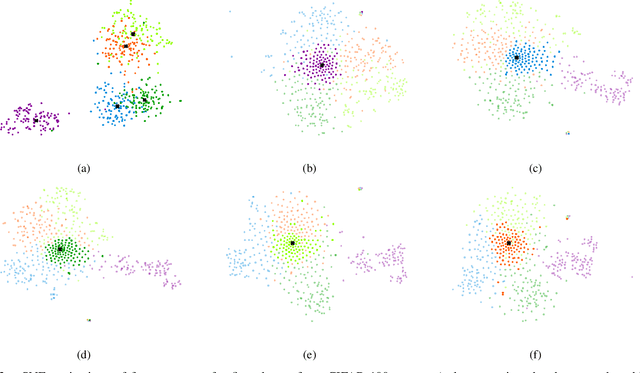
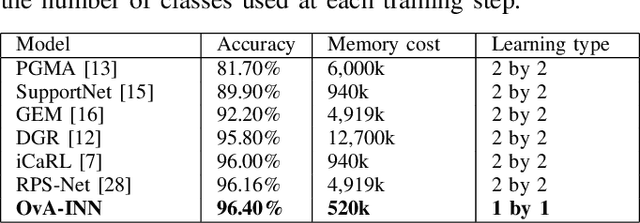
In the field of Continual Learning, the objective is to learn several tasks one after the other without access to the data from previous tasks. Several solutions have been proposed to tackle this problem but they usually assume that the user knows which of the tasks to perform at test time on a particular sample, or rely on small samples from previous data and most of them suffer of a substantial drop in accuracy when updated with batches of only one class at a time. In this article, we propose a new method, OvA-INN, which is able to learn one class at a time and without storing any of the previous data. To achieve this, for each class, we train a specific Invertible Neural Network to extract the relevant features to compute the likelihood on this class. At test time, we can predict the class of a sample by identifying the network which predicted the highest likelihood. With this method, we show that we can take advantage of pretrained models by stacking an Invertible Network on top of a feature extractor. This way, we are able to outperform state-of-the-art approaches that rely on features learning for the Continual Learning of MNIST and CIFAR-100 datasets. In our experiments, we reach 72% accuracy on CIFAR-100 after training our model one class at a time.
Pavlov's dog associative learning demonstrated on synaptic-like organic transistors
Feb 13, 2013In this letter, we present an original demonstration of an associative learning neural network inspired by the famous Pavlov's dogs experiment. A single nanoparticle organic memory field effect transistor (NOMFET) is used to implement each synapse. We show how the physical properties of this dynamic memristive device can be used to perform low power write operations for the learning and implement short-term association using temporal coding and spike timing dependent plasticity based learning. An electronic circuit was built to validate the proposed learning scheme with packaged devices, with good reproducibility despite the complex synaptic-like dynamic of the NOMFET in pulse regime.