 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExtracting Latent Steering Vectors from Pretrained Language Models
May 10, 2022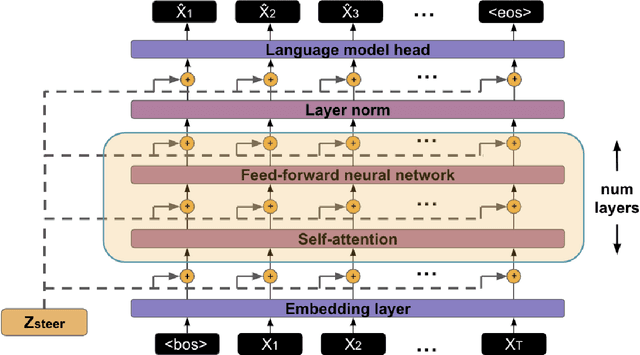



Prior work on controllable text generation has focused on learning how to control language models through trainable decoding, smart-prompt design, or fine-tuning based on a desired objective. We hypothesize that the information needed to steer the model to generate a target sentence is already encoded within the model. Accordingly, we explore a different approach altogether: extracting latent vectors directly from pretrained language model decoders without fine-tuning. Experiments show that there exist steering vectors, which, when added to the hidden states of the language model, generate a target sentence nearly perfectly (> 99 BLEU) for English sentences from a variety of domains. We show that vector arithmetic can be used for unsupervised sentiment transfer on the Yelp sentiment benchmark, with performance comparable to models tailored to this task. We find that distances between steering vectors reflect sentence similarity when evaluated on a textual similarity benchmark (STS-B), outperforming pooled hidden states of models. Finally, we present an analysis of the intrinsic properties of the steering vectors. Taken together, our results suggest that frozen LMs can be effectively controlled through their latent steering space.
Discovering Useful Sentence Representations from Large Pretrained Language Models
Aug 20, 2020
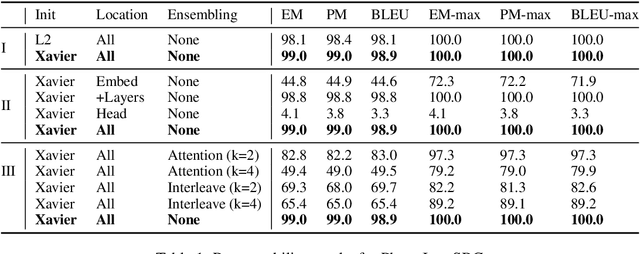

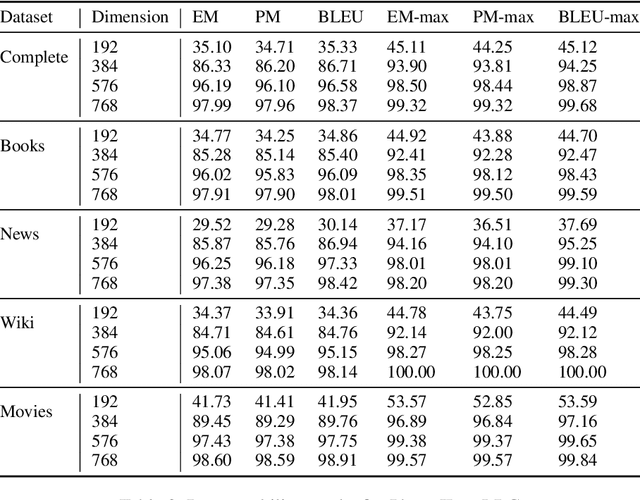
Despite the extensive success of pretrained language models as encoders for building NLP systems, they haven't seen prominence as decoders for sequence generation tasks. We explore the question of whether these models can be adapted to be used as universal decoders. To be considered "universal," a decoder must have an implicit representation for any target sentence $s$, such that it can recover that sentence exactly when conditioned on its representation. For large transformer-based language models trained on vast amounts of English text, we investigate whether such representations can be easily discovered using standard optimization methods. We present and compare three representation injection techniques for transformer-based models and three accompanying methods which map sentences to and from this representation space. Experiments show that not only do representations exist for sentences from a variety of genres. More importantly, without needing complex optimization algorithms, our methods recover these sentences almost perfectly without fine-tuning the underlying language model at all.