Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHinglishNLP: Fine-tuned Language Models for Hinglish Sentiment Detection
Aug 22, 2020

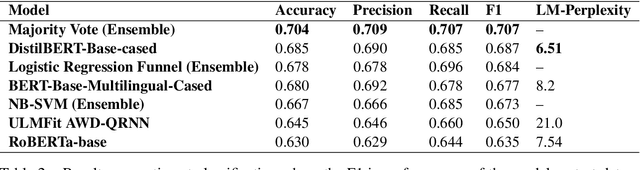
Sentiment analysis for code-mixed social media text continues to be an under-explored area. This work adds two common approaches: fine-tuning large transformer models and sample efficient methods like ULMFiT. Prior work demonstrates the efficacy of classical ML methods for polarity detection. Fine-tuned general-purpose language representation models, such as those of the BERT family are benchmarked along with classical machine learning and ensemble methods. We show that NB-SVM beats RoBERTa by 6.2% (relative) F1. The best performing model is a majority-vote ensemble which achieves an F1 of 0.707. The leaderboard submission was made under the codalab username nirantk, with F1 of 0.689.
* SemEval 2020
Via